SynGen

SynGen is a subsidiary of Avant-Garde-Technologies that is engaged in biotechnology. SynGen participates in the genetic engineering and development of new meds as a contract pharmaceutical research and development biotechnology for plants and organisms. To summarize briefly the biotech activities of SynGen are directed toward manipulating organisms and components of life in order to develop new products and processes. This includes R&D related to the physical, chemical, and genetic aspects of cells and tissues. For example, biotechnology is used to create drugs that are generated by bacteria that have modified genomes, such as for producing insulin.
The quantum simulation of DNA repair focuses on modeling the intricate chemical and electronic events that occur during the damage and subsequent restoration of the DNA molecule. These processes are inherently quantum mechanical and are therefore computationally intractable for even the most powerful classical supercomputers.
Here is a detailed explanation of how QAI (specifically Quantum Simulation) is applied to DNA repair:
The Quantum Challenge in DNA Repair
DNA damage and repair often involve transient, high-energy chemical states, where the movement and interaction of electrons dictate the outcome. These processes are challenging for classical computers because:
Electronic Structure: Modeling the exact location and energy of all electrons in the large, complex molecules (like DNA bases, repair enzymes, and cofactors) is essential for accurate simulation. The number of variables grows exponentially with the size of the molecule.
Chemical Reactions (Bond Breaking/Forming): When DNA is damaged or an enzyme cuts/pastes a base, new chemical bonds are broken and formed. Simulating these changes requires solving the Schrödinger equation, a fundamental equation of quantum mechanics, which is too complex for classical hardware in biological-scale systems.
Quantum Tunneling: In some enzymatic reactions, protons (hydrogen nuclei) may "tunnel" through energy barriers rather than jumping over them. This purely quantum mechanical phenomenon is critical for understanding the speed and efficiency of certain repair steps, and it cannot be reliably modeled using classical physics approximations.
How Quantum Simulation Solves the Problem
A quantum computer, using qubits instead of classical bits, is fundamentally designed to store and process information based on quantum mechanical principles (superposition and entanglement). This allows it to perform simulations that are impossible for classical machines:
Simulation Goal Classical Limitations Quantum Solution (QAI)
Electronic Structure Uses approximations (e.g., Density Functional Theory) that sacrifice accuracy for speed. Directly maps the electronic wave function onto qubits, allowing for exact, non-approximate solutions of the molecular energy (e.g., via the Variational Quantum Eigensolver, or VQE).

QAI (Quantum Artificial Intelligence) represents the powerful convergence of Quantum Computing and Artificial Intelligence (specifically, Quantum Machine Learning), and it has revolutionized both genetic engineering and drug discovery by tackling computational problems currently intractable for classical supercomputers.
Here is a breakdown of how QAI will innovate these fields:
IInnovation in Drug Discovery
The drug discovery process is slow, expensive, and fails over 90% of the time. QAI offers the potential to collapse the timescale and increase the success rate by providing unparalleled simulation power.
Ultra-Accurate Molecular Simulation (Quantum Chemistry)
The Problem: The most precise interactions between a drug molecule and a protein target (binding affinity) are governed by the laws of quantum mechanics. Classical computers must use simplifying approximations, which leads to errors and failed drug candidates.
The QAI Innovation: A quantum computer can directly simulate the exact quantum mechanical behavior of molecules and their electronic structure. This will enable:
Precise Binding Prediction: Accurately predicting how a drug candidate will bind to a target protein, including its efficacy and potential side effects, with unprecedented precision.
Targeting "Undruggable" Proteins: Accurately modeling complex and flexible proteins (like KRAS, a key cancer target) that currently evade classical simulation techniques.
Accelerated Hit Identification and Lead Optimization
The Problem: Scientists must search through a vast chemical space (the theoretical universe of all possible molecules) to find a good drug candidate. This space is too large for classical computers to explore fully.
The QAI Innovation: Quantum Machine Learning (QML) algorithms can use the principles of superposition and entanglement to explore this chemical space exponentially faster.
Generative Drug Design: QML models can be trained to generate entirely new molecular structures that possess desired properties (e.g., high efficacy, low toxicity) rather than just screening existing ones.
Optimization: QAI can solve complex optimization problems to rapidly refine a lead compound's structure to make it more effective, safer, and easier to manufacture.
IInnovation in Genetic Engineering (Genomics and Personalized Medicine)
QAI's ability to analyze massive, highly dimensional datasets and simulate complex biological systems will transform our understanding and modification of the genome.
Precision Gene-Editing with CRISPR-Cas Optimization
The Problem: Tools like CRISPR-Cas have off-target effects, meaning they can cut DNA in unintended places, which is a major safety concern. The efficiency of the guide RNA is difficult to predict with classical methods.
The QAI Innovation: QAI can process multi-omics data (genomics, transcriptomics, proteomics) and leverage quantum chemical features to:
Predict CRISPR Efficiency: Use quantum properties to more accurately predict the on-target vs. off-target activity of a guide RNA, allowing for the design of perfect, error-free editing systems.
Simulate DNA Repair: Model the complex cellular DNA repair pathways following a cut, providing insight on how to genetically engineer cells for higher-fidelity repair.
Advanced Genomic Analysis and Personalized Medicine
The Problem: Analyzing and linking millions of genetic variants across thousands of patients to specific diseases or drug responses (Pharmacogenomics) is an immense data challenge due to non-linear and cryptic relationships.
The QAI Innovation: QML excels at pattern recognition in high-dimensional data, making it ideal for genomics:
Biomarker Discovery: QAI can uncover subtle, complex relationships (cryptic population structure) within genomic data that point to new disease biomarkers or drug targets that classical AI misses.
Personalized Treatment Planning: By integrating a patient's individual genomic data, proteomic profile, and clinical history, QAI can create a highly complex, personalized model to predict their exact disease trajectory and optimal drug dosage/combination.
Area of Innovation QAI Advantage Outcome
Drug Binding Quantum Simulation 100% accurate prediction of drug-protein interaction, drastically reducing clinical trial failures.
Molecular Design Quantum Machine Learning (Generative AI) Rapid design of novel, optimized molecules for previously "undruggable" targets.
Gene Editing Quantum Feature Analysis Error-free CRISPR-Cas systems by precisely predicting and eliminating off-target edits.
Genomics QML for Pattern Recognition Discovery of hidden biomarkers and real-time personalized medicine treatment plans.
Specific Applications in DNA Repair
Quantum simulation is targeted at gaining fundamental insights into key repair mechanisms:
A. Simulating Photodamage and Repair (Base Excision Repair)
The process: UV light can cause chemical damage (like the formation of cyclobutane pyrimidine dimers, or CPDs) that must be excised and replaced.
QAI's Role: Simulating how repair enzymes, such as photolyase, recognize and repair this damage. Photolyase uses a light-activated chemical process to "undo" the damage. QAI can simulate the precise electron transfer and energy state changes within the photolyase molecule, explaining its near-perfect efficiency in repairing the damaged DNA.
Understanding Mutagenesis and Polymerase Fidelity
The process: DNA polymerase enzymes copy DNA, but occasionally make errors, leading to mutations.
QAI's Role: Simulating the moments when an incorrect base is being incorporated. QAI can calculate the subtle quantum forces that govern the hydrogen bonding between bases, identifying why a polymerase might accept an incorrect base (leading to a mutation) or reject it (ensuring high fidelity). This can lead to the design of new, ultra-fidelity polymerases for gene editing.
Improving Gene Editing Systems
The process: CRISPR and related gene-editing tools require the cell's natural DNA repair machinery (Non-Homologous End Joining or Homology-Directed Repair) to fix the break.
QAI's Role: Simulating the complex and variable mechanisms of the repair pathways themselves. This could reveal how to chemically or genetically steer the cell's repair response towards the desired outcome (e.g., high-precision insertion of a new gene) and away from error-prone outcomes (e.g., deletions that deactivate the gene).
In essence, QAI provides the ultimate computational microscope, allowing scientists to see and manipulate the electron dynamics and chemical bond transformations that are the very definition of DNA damage and repair.

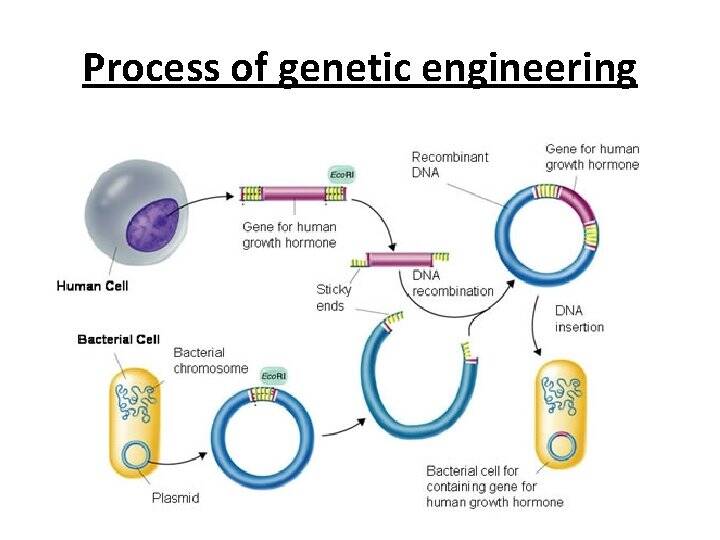
Genetic engineering is the process of using recombinant DNA (rDNA) technology to alter the genetic makeup of an organism. Genetic engineering involves the direct manipulation of one or more genes. Most often, a gene from another species is added to an organism's genome to give it a desired phenotype.
Genetic Engineering has several major segments:
- Accessing the Germline of Animals. Germline refers to the lineage of cells that can be genetically traced from parent to offspring.
- Transfection.
- Retroviral Vectors.
- Transposons
- Knock-In and Knock-Out Technology.
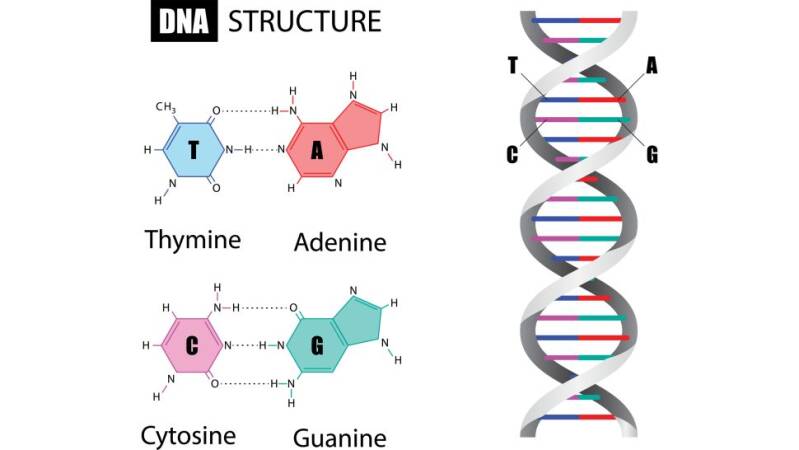
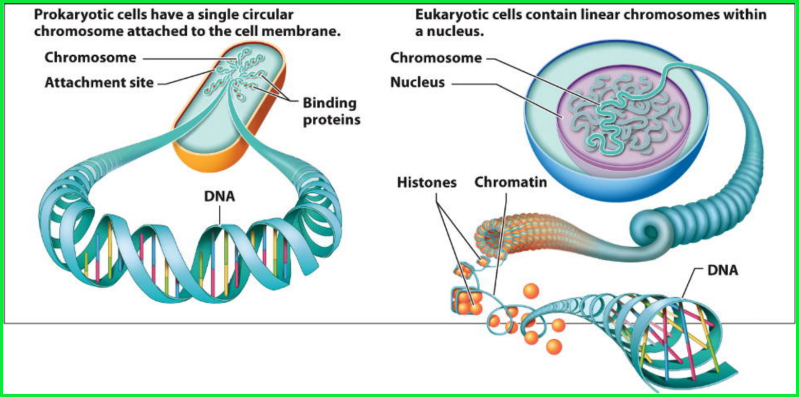
It is fundamental to understand the structure and basic components of DNA. This makes up the genetic code that is found in all living organisms. DNA, or deoxyribonucleic acid, is the hereditary material in humans and almost all other organisms. Nearly every cell in a person’s body has the same DNA. Most DNA is located in the cell nucleus (where it is called nuclear DNA), but a small amount of DNA can also be found in the mitochondria (where it is called mitchondrial DNA (mtDNA). Mitochondria are structures within cells that convert the energy from food into a form that cells can use.
The information in DNA is stored as a code made up of four chemical bases: adenine (A), guanine (G), cytosine (C), and thymine (T). Human DNA consists of about 3 billion bases, and more than 99 percent of those bases are the same in all people. The order, or sequence, of these bases determines the information available for building and maintaining an organism, similar to the way in which letters of the alphabet appear in a certain order to form words and sentences.
Impossible Dream

SynGen major areas for R&D include genetic engineering, molecular genetics, proteins, synthetic biolechnology and other biotech areas that are fundamental to understand for future development of biotechnology products. SysGen has ongoing R&D projects within its specific divisions that include medical, agricultural and industrial. The SysGen medical biotechnology provides R&D for developing vaccines and antibodies and medical diagnostic tests. SysGen’s agricultural biotechnology division is engaged in developing pest resistant crops. SysGen’s industrial division does R&D for development of biocatalysts.
For example, there are five processes for plant and crop genetic engineering that includes:
DNA bases pair up with each other, A with T and C with G, to form units called base pairs. Each base is also attached to a sugar molecule and a phosphate molecule. Together, a base, sugar, and phosphate are called a nucleotide. Nucleotides are arranged in two long strands that form a spiral called a double helix. The structure of the double helix is somewhat like a ladder, with the base pairs forming the ladder’s rungs and the sugar and phosphate molecules forming the vertical sidepieces of the ladder.
An important property of DNA is that it can replicate, or make copies of itself. Each strand of DNA in the double helix can serve as a pattern for duplicating the sequence of bases. This is critical when cells divide because each new cell needs to have an exact copy of the DNA present in the old cell.


A gene is the basic physical and functional unit of heredity. Genes are made up of DNA. Some genes act as instructions to make molecules called proteins. However, many genes do not code for proteins. In humans, genes vary in size from a few hundred DNA bases to more than 2 million bases. An international research effort called the Human Genome Project, which worked to determine the sequence of the human genome and identify the genes that it contains, estimated that humans have between 20,000 and 25,000 genes.
Every person has two copies of each gene, one inherited from each parent. Most genes are the same in all people, but a small number of genes (less than 1 percent of the total) are slightly different between people. Alleles are forms of the same gene with small differences in their sequence of DNA bases. These small differences contribute to each person’s unique physical features.
Scientists keep track of genes by giving them unique names. Because gene names can be long, genes are also assigned symbols, which are short combinations of letters (and sometimes numbers) that represent an abbreviated version of the gene name. For example, a gene on chromosome7 that has been associated with cystic-fibrosis is called the cystic fibrosis transmembrane conductance regulator; its symbol is CFTR.
Genetic Engineering
Genetic engineering is SynGen’s main focus. It primarily involves molecular biology that are represented by living genomes of living organisms. These genomes can be modified by a gene editing technique known as Clusters of Regularly Interspaced Short Palindromic Repeats (CRISPR) which describes a region of DNA consisting of short, repeated sequences referred to as “spacers” that are located between each repeat. Repeats in the genetic code are the ordering rungs within the spiral DNA molecule. Each rung contains two chemical bases bound together, e.g., Adenine (A) links with Thymine (T) and Guanine (G) links with Cytosine (C) base.
Imagine

The potential for quantum simulation in DNA repair is immense, but the technology is still in its nascent stage, facing significant barriers related to hardware and the complexity of biological systems.
Here are the current major limitations of using quantum simulation for DNA repair:
Hardware Limitations: The NISQ Era
The current state of quantum hardware—often referred to as Noisy Intermediate-Scale Quantum (NISQ)—is the primary bottleneck:
Limited Qubit Count: DNA repair involves large biomolecules (DNA, repair enzymes, water molecules, cofactors). Simulating even a small section of a protein's active site requires hundreds to thousands of qubits. Current quantum computers typically offer only tens to a few hundred functional qubits, which is not enough to encode the complexity of a biologically relevant system.
Noise and Decoherence: Qubits are extremely sensitive to environmental noise, which causes them to lose their fragile quantum state (decoherence) very quickly. This noise introduces errors into calculations. Since simulations of chemical reactions require running many sequential operations (deep circuits), the cumulative error quickly overwhelms the calculation, making the results unreliable.
Lack of Fault Tolerance: Current machines lack the necessary advanced Quantum Error Correction (QEC), which uses many physical qubits to create a single, highly reliable "logical qubit." Until fault-tolerant quantum computers are realized, the accuracy needed for fundamental molecular simulation will remain out of reach.
Scalability and System Size
DNA repair is a local event that takes place within a large, dynamic environment. Simulating this requires modeling the molecular system and its surroundings:
System Truncation: To fit onto current hardware, researchers must heavily simplify the system, modeling only a few atoms in the enzyme's active site. This ignores the crucial solvation effects (the influence of surrounding water molecules) and the dynamic effects of the rest of the large enzyme, which are essential for biological accuracy.
Scaling Algorithms (Memory): While quantum algorithms promise exponential speed-up, they still require a way to efficiently load the huge amount of classical input data (molecular coordinates, electronic integrals) into the quantum computer (qRAM). Efficient, reliable qRAM has not yet been practically developed, forcing near-term applications to rely on inefficient data encoding methods.
Simulation Time-Scales (Dynamics)
Molecular processes like DNA repair are dynamic, taking place over short time periods. Quantum simulation still struggles to capture this:
Static vs. Dynamic: Current quantum chemistry algorithms (like VQE for energy calculations) are best suited for finding the lowest energy state (static properties) of a small molecule. Accurately simulating a dynamic chemical reaction—the bond breaking, electron transfer, and nuclear movement over time—is a much harder challenge that requires more robust and error-resistant quantum dynamics algorithms.
Classical Integration: Most current practical applications rely on a hybrid quantum-classical approach. The quantum computer handles only the small, quantum-critical part of the system, while a classical supercomputer handles the rest (e.g., the molecular dynamics of the protein backbone). The interface and efficiency of this handoff remain complex and need significant optimization.
In summary, the limitations stem not from the theory—quantum mechanics is the correct language for these problems—but from the immaturity of the hardware. Achieving biologically relevant, high-fidelity quantum simulations of DNA repair requires overcoming the noisy, limited capacity of the NISQ era and ushering in the age of large-scale, fault-tolerant quantum computing.

Palindromic sequences are repeated base sequences are in the CRISPR region where the bases are in the same order multiple times. The bases on one side of the DNA molecule match those on the opposite side when they are read in opposite directions. Palindromic repeats are found throughout CRISPR DNA regions. Each palindromic sequence has a spacer at its end. When CRISPR Cas9 protein is added to the cell with a piece of guide RNA, the Cas9 protein hooks up with the guide RNA and moves along the strands of DNA until it finds and binds to the 20-DNA-letter long sequence that matches part of the guide RNA sequence. For example, the standard Cas9 protein cuts the DNA at the target site and when the cut is repaired, mutations are introduced that disables the gene.
.
CRISPR can be used for editing, It can make precise changes, such as replacing faulty a gene with a good gene that corrects the mistake. CRISPRa and CRISPRi Cas proteins can also be used to turn genes off or on. They can also change one letter of the DNA code to another.
The manner which CRISPR works was discovered in bacteria. It was discovered that bacteria swipe the spacers from viruses that attack them and incorporate some of the viral DNA into their own genome. The spacers serve as memories that allow bacteria to recognize the viruses once they are attacked. CRISPR was discovered that after a virus attack, the bacteria incorporated the new spacers into their CRISPR regions and the spacers were identical to parts of the virus genome. CRISPR can be used to alter the bacteria’s resistance to a specific virus and created bacteria immunity to the virus. CRISPR functions by using the Cas9 nuclease complexed with synthetic guide RNA (gRNA) into the cell which causes the cell’s genome to be cut at a desired location.
Never ending story

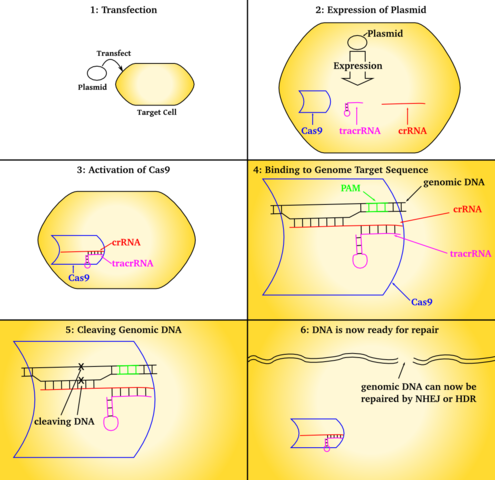
CRISPR allows existing genes to be removed or new ones added. CRISPR is used to create new medicines, agricultural products, genetically modified to control pathogens and pests. It is also used for the treatment of inherited genetic diseases and somatic mutations, such as cancer. CRISPR-Cas9 genetic engineering is also used to generate targeted random gen disruption with precision of genome editing for modification of eukaryotic cells. It does this by targeting a break in a specific location designated by the crRNA and tracrRNA guide strands.
Molecular Genetics (MG)
SynGen has division engaged in R&D of Molecular Genetics which relates to the structure and function of genes at the molecular level. This is genetic engineering that directly manipulates an organism’s genome. MG is also applied to identifying genetic markers that result in different phenotypes. MG is the foundation for molecular and cellular biology that enable genes to encode proteins. It will be from MG that personalized medicine develop. Since CRISPR is technology used in molecular genetics, it will be elaborated here.

Sweet Dreams are made of this
CRISPR is a powerful tool for editing genomes, meaning it allows researchers to easily alter DNA sequences and modify gene function. It has many potential applications, including correcting genetic defects, treating and preventing the spread of diseases, and improving the growth and resilience of crops.
CRISPR is a family of DNA sequences found in the genomes of prokaryotic organisms such as bacteria and archaea. These sequences are derived from DNA fragments of bacteriophages that had previously infected the prokaryote. They are used to detect and destroy DNA from similar bacteriophages during subsequent infections.
CRISPR is a technology that can be used to edit genes and, as such, will likely change the world. The essence of CRISPR is simple: it's a way of finding a specific bit of DNA inside a cell. After that, the next step in CRISPR gene editing is usually to alter that piece of DNA.
CRISPR is a powerful tool for editing genomes, meaning it allows researchers to easily alter DNA sequences and modify gene function. It has many potential applications, including correcting genetic defects, treating and preventing the spread of diseases, and improving the growth and resilience of crops.
CRISPR" is actually means for "CRISPR-Cas9." CRISPRs are specialized stretches of DNA, and the protein Cas9 — where Cas stands for "CRISPR-associated" — is an enzyme that acts like a pair of molecular scissors, capable of cutting strands of DNA.
CRISPR technology was adapted from the natural defense mechanisms of bacteria and archaea, a domain of relatively simple single-celled microorganisms. These organisms use CRISPR-derived RNA, a molecular cousin to DNA, and various Cas proteins to foil attacks by viruses. To foil attacks, the organisms chop up the DNA of viruses and then stow bits of that DNA in their own genome, to be used as a weapon against the foreign invaders should those viruses attack again.
CRISPR technology was adapted from the natural defense mechanisms of bacteria and archaea, a domain of relatively simple single-celled microorganisms. These organisms use CRISPR-derived RNA, a molecular cousin to DNA, and various Cas proteins to foil attacks by viruses. To foil attacks, the organisms chop up the DNA of viruses and then stow bits of that DNA in their own genome, to be used as a weapon against the foreign invaders should those viruses attack again.
When the components of CRISPR are transferred into other, more complex, organisms, those components can then manipulate genes, a process called "gene editing."
CRISPRs:
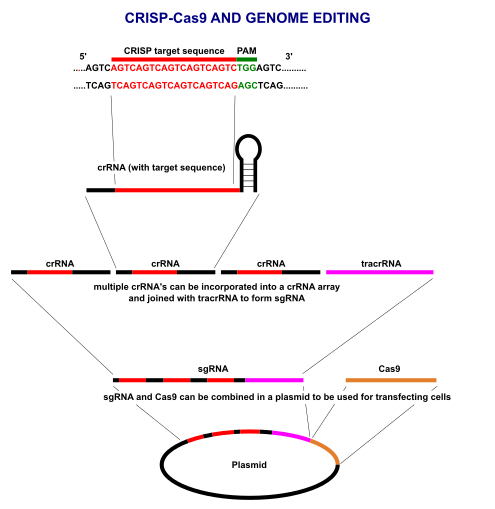
The term "CRISPR" stands for "clusters of regularly interspaced short palindromic repeats" and describes a region of DNA made up of short, repeated sequences with so-called "spacers" sandwiched between each repeat.
When we talk about repeats in the genetic code, we're talking about the ordering of rungs within the spiral ladder of a DNA molecule. Each rung contains two chemical bases bound together: A base called adenine (A) links up to another called thymine (T), and the base guanine (G) pairs with cytosine (C).
In a CRISPR region, these bases appear in the same order several times, and in these repeated segments, they form what's known as "palindromic" sequences. A palindrome, like the word "racecar," reads the same forward as it does backward; similarly, in a palindromic sequence, bases on one side of the DNA ladder match those on the opposing side when you read them in opposite directions.

For example, a super simple palindromic sequence might look like this:
- Side 1 - GATC
- Side 2 - CTAG
Short palindromic repeats appear throughout CRISPR regions of DNA, with each repeat bookended by "spacers." Bacteria swipe such spacers from viruses that have attacked them, meaning they incorporate a bit of viral DNA into their own genome. These spacers serve as a bank of memories, which enables the bacteria to recognize the viruses if they should ever attack again. You can also think of spacers like "Wanted" posters, providing a snapshot of the bad guys so they can be easily spotted and brought to justice.
CRISPR RNA (crRNA):
CRISPR regions of DNA act as a kind of bank of viral memories; but for that stored information to be useful elsewhere in the cell, it must be copied, or "transcribed," into a different genetic molecule called RNA. Unlike DNA sequences, which remain lodged inside the DNA molecule, this CRISPR RNA (crRNA) can roam about the cell and team up with proteins — namely the molecular scissors that snip viruses to bits.

RNA also differs from DNA in that it's only one strand, rather than two, meaning it looks like just a half of a ladder. To build an RNA molecule, one part of the CRISPR acts as a template and proteins called polymerases swoop in to construct an RNA molecule that is "complementary" to that template, meaning the two strands' bases would fit together like puzzle pieces. For example, a G in the DNA molecule would get transcribed as a C in the RNA.
Each snippet of CRISPR RNA contains a copy of a repeat and a spacer from a CRISPR region of DNA, The crRNA interacts with the Cas9 protein and another kind of RNA, called "trans-activating crRNA" or tracrRNA, in order to help bacteria fend off viruses.
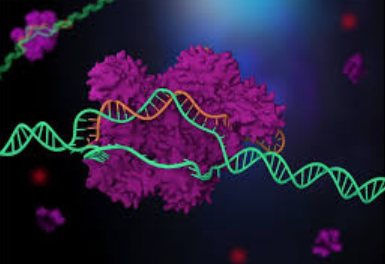
Cas9:
The Cas9 protein is an enzyme that cuts foreign DNA. The protein binds to crRNA and tracrRNA, which together guide Cas9 to a target site on the virus's DNA strand where the protein will make its cut. The target DNA that the Cas9 will cut through is complementary to a 20-nucleotide stretch of the crRNA, where a "nucleotide" is a building block of DNA that contains one base.
Using two separate regions or "domains" on its structure, Cas9 cuts both strands of the DNA double helix, making what is known as a "double-stranded break."


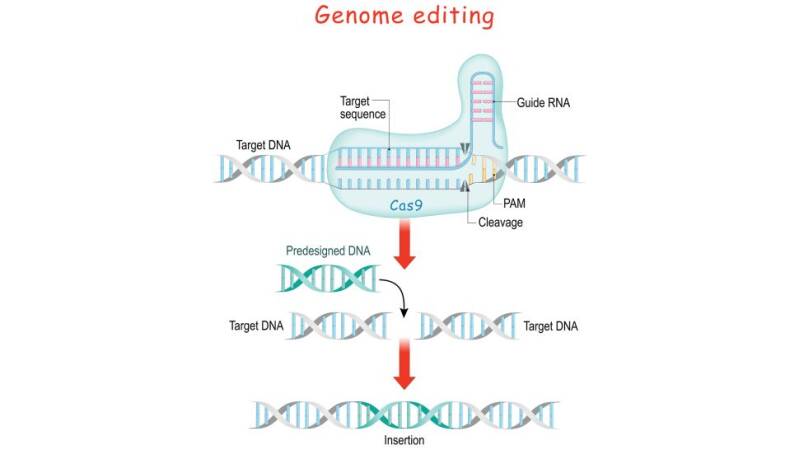
Genomes encode a series of messages and instructions within their DNA sequences, and genome editing involves changing those sequences, thereby changing the messages they contain. This can be done by inserting a cut or break in the DNA and tricking a cell's natural DNA repair mechanisms into introducing the targeted changes. CRISPR-Cas9 provides a means to do so.
There is a built-in safety mechanism that ensures that Cas9 doesn't just cut just anywhere in a genome. Short DNA sequences known as "protospacer adjacent motifs," or PAMs, serve as tags and sit adjacent to the target DNA sequence. If the Cas9 complex doesn't see a PAM next to its target DNA sequence, it won't cut. This is one possible reason that Cas9 doesn't ever attack the CRISPR region in bacteria
CRISPR-Cas9 could be used to chop up any DNA, not just that of viruses. In this way, the natural CRISPR system could be transformed into a simple, programmable genome-editing tool.
To direct Cas9 to snip a specific region of DNA, scientists can simply change the sequence of the crRNA, which binds to a complementary sequence in the target DNA

By fusing crRNA and tracrRNA to create a single "guide RNA," genome editing can be performed, since it requires only a guide RNA and the Cas9 protein. Operationally, you design a stretch of 20 base pairs that match a gene that you want to edit, and from there, one can figure out what the complementary crRNA sequence would be. It Is necessary to make sure that the nucleotide sequence is found only in the target gene and nowhere else in the genome.
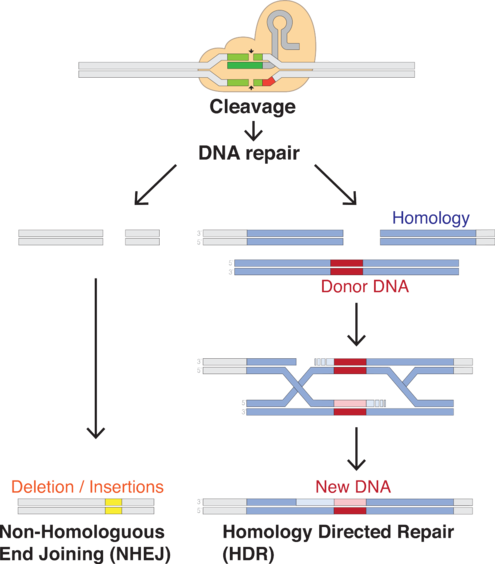
The RNA plus the protein [Cas9] will cut the DNA at that site, and nowhere else. Once the DNA is cut, the cell's natural repair mechanisms kick in and work to piece the DNA back together, and at this point, edits can be made to the genome. There are two ways this can happen.
The first repair method involves gluing the two cuts back together. This method, known as "non-homologous end joining," tends to introduce errors where nucleotides are accidentally inserted or deleted, resulting in mutations that could disrupt a gene.
In the second method, the break is fixed by filling in the gap with a sequence of nucleotides. In order to do so, the cell uses a short strand of DNA as a template. Scientists can supply the DNA template of their choosing, thereby writing-in any gene they want, or correcting a mutation.
Cas genes and the function of Cas enzymes together with the tracrRNA is molecular scissors was the foundation for creating a gene-editing tool. This has enabled CRISPR gene-editing technology in eukaryotes, or complex cells with nuclei to hold their DNA.
Although CRISPR is idea of using gene editing clinically to cure disease, CRISPR technology can be applied in the food and agricultural industries to engineer probiotic cultures and to vaccinate industrial cultures like yogurt against viruses. Also CRISPR can be used in crops to improve yield, drought tolerance and nutritional properties.
CRISPR can also be used for making genetic modifications to human embryos and reproductive cells such as sperm and eggs is known as germline editing. These genetic changes to these cells can be passed on to subsequent generations


CRISPR can be used to create gene drives, a genetic engineering technique that increases the chances of a particular trait passing on from parent to offspring; this kind of genetic engineering derives from a natural phenomenon, where specific versions of genes are more likely to be inherited. Over the course of generations, the trait spreads through entire populations. Gene drives could be used for various applications, such as eradicating invasive species or reversing pesticide and herbicide resistance in crops
Proteins
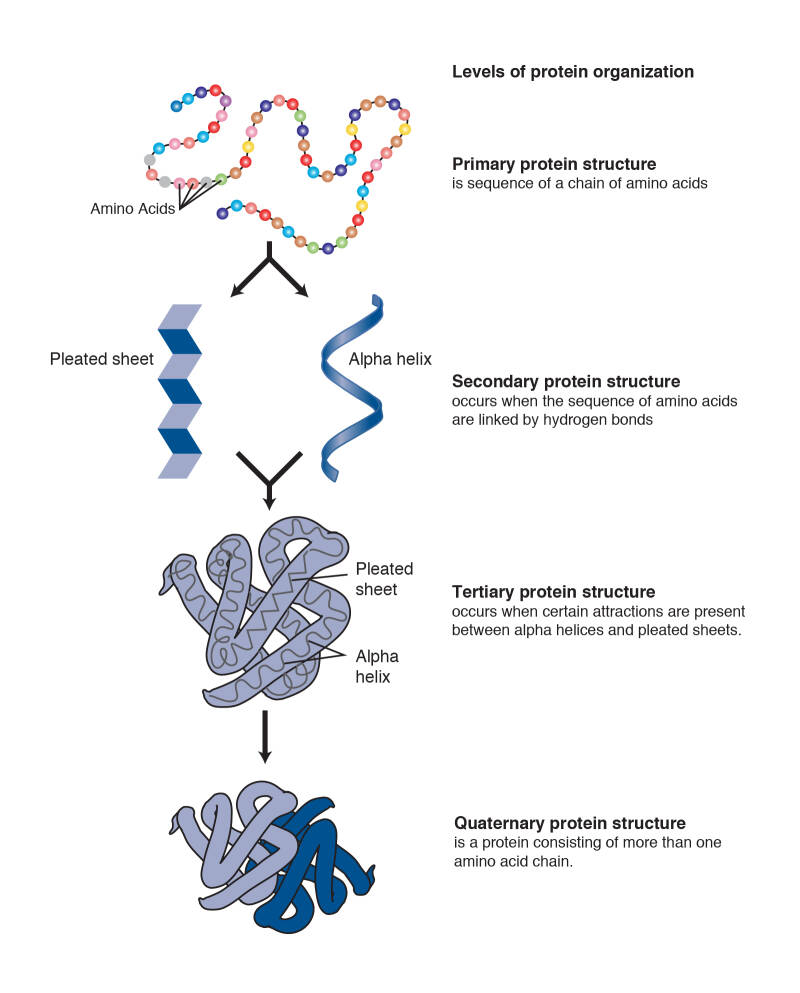
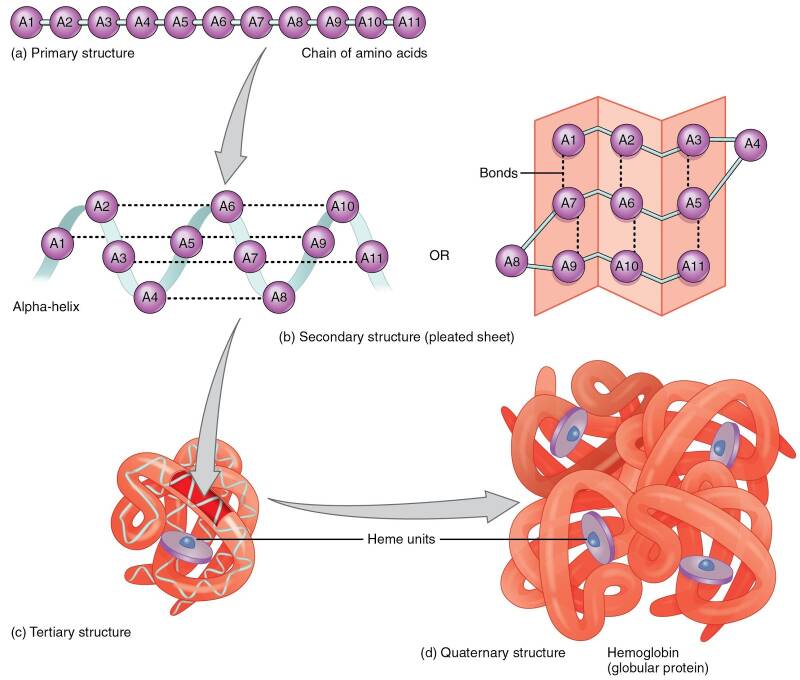
Pharmaceutical development for therapeutics often involves protein R&D which is extremely difficult. The nature of protein structures and their conformational characteristics of specific proteins is critical to developing new pharmaceuticals. Proteins can be extremely complex macromolecules that have the four different levels of structure: Primary, Secondary, Tertiary, and Quaternary.

There are 20 L-alpha amino acids are used by cells to create proteins. Amino acids contain a basic amino group and acidic carboxyl group which allows amino acids to join in long chains by forming peptide bonds between the –NH2 of one amino acid and the –COOH of another amino acid. Sequences of fewer than 40 amino acids are known as peptides, while longer sequences are known as polypeptide. One end of the peptide ends with carboxy-terminus (C-terminus) and the other ends with amino-terminus (N-terminus).
Proteins consist of multiple peptides. Side chains in the structure confer different chemical, physical and structural properties to the protein. There are 20 amino acids required to create human proteins, only 10 can be synthesized. The other 10 are known as essential amino acids and provided through the foods consumed.
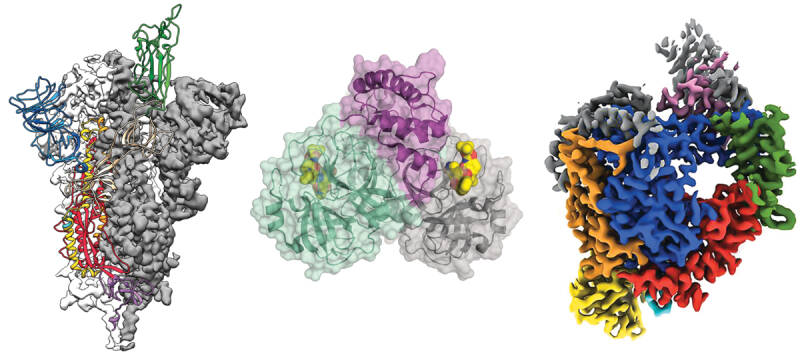
Amino acid sequence in proteins is encoded in the DNA which enables to be synthesized through transcription that uses a DNA strand to make a complementary messenger RNA strand (mRNA) and translation. This process uses the mRNA sequences as a template to guide the synthesis of the chain of amino acids that make up the protein. There are also other processes, such as glycosylation and phosphorylation, that enable the biological function of the protein. The chemical and biological properties of proteins are dependent on the 3-dimensional or tertiary structure.
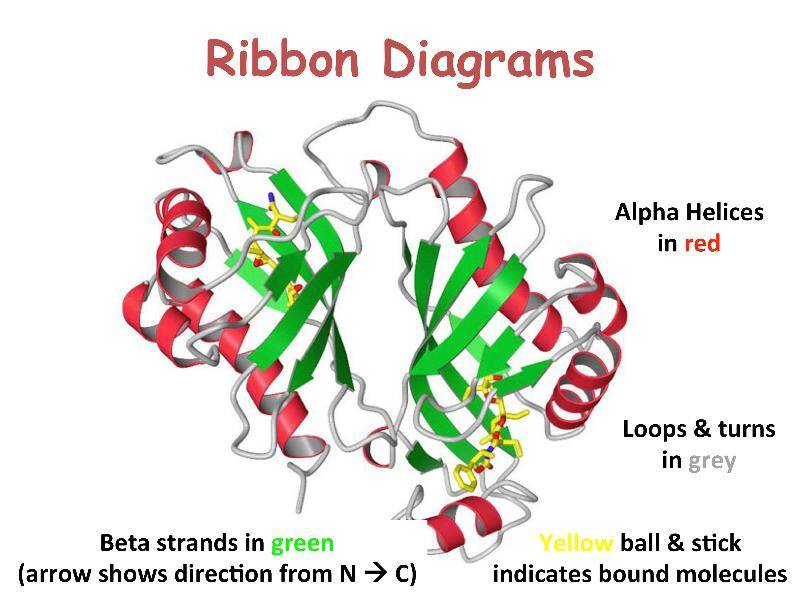
Stretches or strands of proteins or peptides have distinct, characteristic local structural conformations, or secondary structure, dependent on hydrogen bonding. The two main types of secondary structure are the α-helix and the ß-sheet.
The α-helix is a right-handed coiled strand. The side-chain substituents of the amino acid groups in an α-helix extend to the outside. Hydrogen bonds form between the oxygen of each C=O bond in the strand and the hydrogen of each N-H group four amino acids below it in the helix. The hydrogen bonds make this structure especially stable. The side-chain substituents of the amino acids fit in beside the N-H groups.
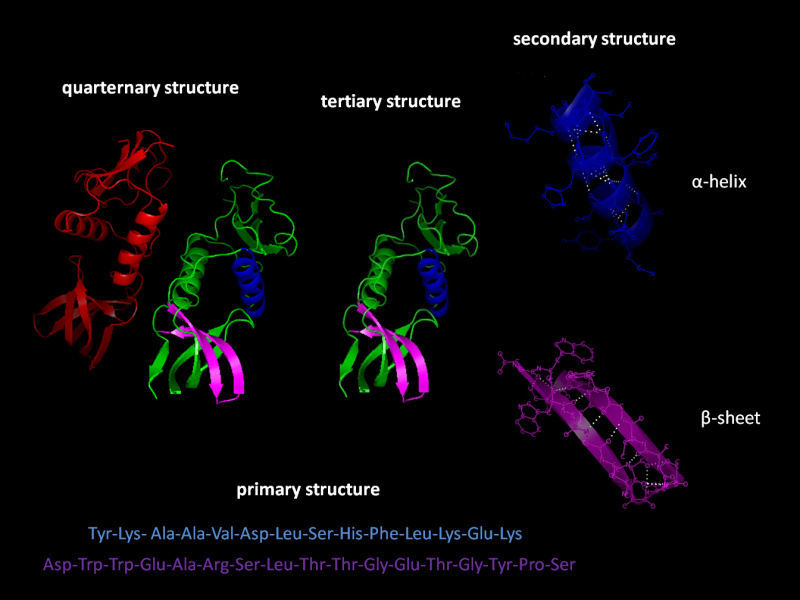
The hydrogen bonding in a ß-sheet is between strands (inter-strand) rather than within strands (intra-strand). The sheet conformation consists of pairs of strands lying side-by-side. Carbonyl oxygens in one strand bond with the amino hydrogens of the adjacent strand. The two strands can be either parallel or anti-parallel depending on whether the strand directions (N-terminus to C-terminus) are the same or opposite. The anti-parallel ß-sheet is more stable due to the more well-aligned hydrogen bonds.
The overall three-dimensional shape of a protein molecule is the tertiary structure. The protein molecule will bend and twist in such a way as to achieve maximum stability or lowest energy state. Although the three-dimensional shape of a protein may seem irregular and random, it is fashioned by many stabilizing forces due to bonding interactions between the side-chain groups of the amino acids.

Under physiologic conditions, the hydrophobic side-chains of neutral, non-polar amino acids such as phenylalanine or isoleucine tend to be buried on the interior of the protein molecule, thereby shielding them from the aqueous medium. The alkyl groups of alanine, valine, leucine and isoleucine often form hydrophobic interactions between one another, while aromatic groups such as those of phenylalanine and tyrosine often stack together. Acidic or basic amino acid side-chains will generally be exposed on the surface of the protein as they are hydrophilic.
The formation of disulfide bridges by oxidation of the sulfhydryl groups on cysteine is an important aspect of the stabilization of protein tertiary structure, allowing different parts of the protein chain to be held together covalently. Additionally, hydrogen bonds may form between different side-chain groups. As with disulfide bridges, these hydrogen bonds can bring together two parts of a chain that are some distance away in terms of sequence. Salt bridges, ionic inter- actions between positively and negatively charged sites on amino acid side chains, also help to stabilize the tertiary structure of a protein.


Many proteins are made up of multiple polypeptide chains, often referred to as protein subunits. These subunits may be the same, as in a homodimer, or different, as in a heterodimer. The quaternary structure refers to how these protein subunits interact with each other and arrange themselves to form a larger aggregate protein complex. The final shape of the protein complex is once again stabilized by various interactions, including hydrogen-bonding, disulfide-bridges and salt bridges.
Due to the nature of the weak interactions controlling the three-dimensional structure, proteins are very sensitive molecules. The term native state is used to describe the protein in its most stable natural conformation in situ. This native state can be disrupted by several external stress factors including temperature, pH, removal of water, presence of hydrophobic surfaces, presence of metal ions and high shear. The loss of secondary, tertiary or quaternary structure due to exposure to a stress factor is called denaturation. Denaturation results in unfolding of the protein into a random or misfolded shape.
A denatured protein can have quite a different activity profile than the protein in its native form, usually losing biological function. In addition to becoming denatured, proteins can also form aggregates under certain stress conditions. Aggregates are often produced during the manufacturing process and are typically undesirable, largely due to the possibility of them causing adverse immune responses when administered.
In addition to these physical forms of protein degradation, it is also important to be aware of the possible pathways of protein chemical degradation. These include oxidation, deamidation, peptide-bond hydrolysis, disulfide-bond reshuffling and cross-linking. The methods used in the processing and the formulation of proteins, including any lyophilization step, must be carefully examined to prevent degradation and to increase the stability of the protein biopharmaceutical both in storage and during drug delivery.

The complexities of protein structure make the elucidation of a complete protein structure extremely difficult even with the most advanced analytical equipment. An amino acid analyzer can be used to determine which amino acids are present and the molar ratios of each. The sequence of the protein can then be analyzed by means of peptide mapping and the use of Edman degradation or mass spectroscopy. This process is routine for peptides and small proteins but becomes more complex for large multimeric proteins.
Peptide mapping generally entails treatment of the protein with different protease enzymes to chop up the sequence into smaller peptides at specific cleavage sites. Two commonly used enzymes are trypsin and chymotrypsin. Mass spectroscopy has become an invaluable tool for the analysis of enzyme digested proteins, by means of peptide fingerprinting methods and database searching. Edman degradation involves the cleavage, separation and identification of one amino acid at a time from a short peptide, starting from the N-terminus.
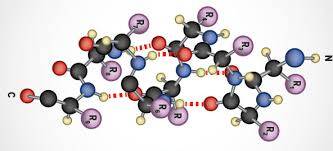
One method used to characterize the secondary structure of a protein is circular dichroism spectroscopy (CD). The different types of secondary structure, α-helix, ß-sheet and random coil, all have characteristic circular dichroism spectra in the far-UV region of the spectrum (190-250 nm). These spectra can be used to approximate the fraction of the entire protein made up of each type of structure.
A more complete, high-resolution analysis of the three-dimensional structure of a protein is carried out using X-ray crystallography or nuclear magnetic resonance (NMR) analysis. To determine the three-dimensional structure of a protein by X-ray diffraction, a large, well-ordered single crystal is required. X-ray diffraction allows measurement of the short distances between atoms and yields a three-dimensional electron density map, which can be used to build a model of the protein structure.
The use of NMR to determine the three-dimensional structure of a protein has some advantages over X-ray diffraction in that it can be carried out in solution and thus the protein is free of the constraints of the crystal lattice. The two-dimensional NMR techniques generally used are NOESY, which measures the distances between atoms through space, and COESY, which measures distances through bonds.
Many different techniques can be used to determine the stability of a protein. For the analysis of unfolding of a protein, spectroscopic methods such as fluorescence, UV, infrared and CD can be used. Thermodynamic methods such as differential scanning calorimetry (DSC) can be useful in determining the effect of temperature on protein stability. Comparative peptide-mapping (usually using LC/MS) is an extremely valuable tool in determining chemical changes in a protein, such as oxidation or deamidation. HPLC is also an invaluable means of analyzing the purity of a protein. Other analytical methods such as SDS-PAGE, iso-electric focusing and capillary electrophoresis can also be used to determine protein stability, and a suitable bio-assay should be used to determine the potency of a protein bio-pharmaceutical. The state of aggregation can be determined by following “particle” size and arrayed instruments are now available to follow this over time under various conditions.

The variety of methods for determining protein stability again emphasizes the complexity of the nature of protein structure and the importance of maintaining that structure for a successful bio-pharmaceutical product.

Synthetic biotechnology
SynGen has a Synthetic biotechnology division engaged that involves manipulation of biological molecules, such as the integration of synthetic amino acids into proteins, DBA synthesis. It also does R&D on the DNA manipulation using synthetic sequences, oligonucleotide synthesis, and protein modification using synthetic compounds. R&D synthetic biotechnology is being conducted to rapidly design, synthesize, test and deploy antigens and variants and develop immunogens. Synthetic biology R&D is also directed toward MicroOrganisms to clean pollutants.
One of the SynGen objectives is to use synthetic biotechnology for industrial-scale cell manufacturing and create innovative cell therapies. The most used techniques for synthetic biotechnology involve reading the DNA code, copying existing DNA sequences and inserting specific DNA sequences into existing DNA strands.