Artificial-Intelligence - Data Science - Business Intelligence - BigData

Artificial Intelligence - Machine-Learning..
Artificial Intelligence - Machine-Learning
Limited memory artificial intelligence has the ability to store previous data and predictions when gathering information and weighing potential decisions — essentially looking into the past for clues on what may come next. Limited memory artificial intelligence is more complex and presents greater possibilities than reactive machines. This is the type of AI that is use widely now.
Limited memory AI is created when a team continuously trains a model in how to analyze and utilize new data or an AI environment is built so models can be automatically trained and renewed. When utilizing limited memory AI in machine learning, six steps must be followed: Training data must be created, the machine learning model must be created, the model must be able to make predictions, the model must be able to receive human or environmental feedback, that feedback must be stored as data, and these these steps must be reiterated as a cycle.
The company is building an Artificial Intelligence Machine Learning Center that will be known as Ramanujan Artificial Intelligence NeuroMorphic Deep Learning Center (RAIN DLC). Computer chip architecture known as neuromorphic has been designed for this purpose. It expected that Artificial Intelligence Deep Machine Learning will be deployed wide-spread and this requires the new neuromorphic analogue architecture. This is the first of 5 large 100 sq-meter data centers that are planned to be build for Deep Machine Learning. One of the greatest advancements in AI is GPT-3, which is able to write new articles, computer code and many other things. It would be difficult to distinguish what it creates from that of a human. However, it has its limitations, because it often does not understand the context in the real world.

There are three major machine learning models that utilize limited memory artificial intelligence:
- Reinforcement learning, which learns to make better predictions through repeated trial-and-error.
- Long Short Term Memory (LSTM), which utilizes past data to help predict the next item in a sequence. LTSMs view more recent information as most important when making predictions and discounts data from further in the past, though still utilizing it to form conclusions
- Evolutionary Generative Adversarial Networks (E-GAN), which evolves over time, growing to explore slightly modified paths based off of previous experiences with every new decision. This model is constantly in pursuit of a better path and utilizes simulations and statistics, or chance, to predict outcomes throughout its evolutionary mutation cycle.
Dolly Parton - 9 to 5


Theory of Mind..
Theory of Mind is the next level of artificial intelligence. It is based on the psychological premise of understanding that other living things have thoughts and emotions that affect the behavior of one’s self. This would mean that AI could comprehend how humans feel and make decisions through self-reflection and determination, and then will utilize that information to make decisions of their own. Essentially, machines would have to be able to grasp and process the concept of “mind,” the fluctuations of emotions in decision making and a litany of other psychological concepts in real time, creating a two-way relationship between people and artificial intelligence. This type of AI has not evolved to this level, but it is expected that with the next 10 years it will be reached.
Once Theory of Mind can be established in artificial intelligence, sometime well into the future, the final step will be for AI to become self-aware. This kind of artificial intelligence possesses human-level consciousness and understands its own existence in the world, as well as the presence and emotional state of others. It would be able to understand what others may need based on not just what they communicate to them but how they communicate it. Self-awareness in artificial intelligence relies both on human researchers understanding the premise of consciousness and then learning how to replicate that so it can be built into machines.
Neuromorphic Computing.
Avant-Garde-Technologies spends a large amount of money on the development of neuromorphic computer processors. This technology will become vastly important in the design in computers that are use for AI and ML. Neuromorphic Computing refers to the designing of computers that are based on the systems found in the human brain and the nervous system.
Driven by the vast potential and ability of the human brain, neuromorphic computing devises computers that can work as efficiently as the human brain without acquiring large room for the placement of software.
Inspired by the human brain and the functioning of the nervous system, Neuromorphic Computing was a concept introduced in the 1980s. Yet this concept has taken the front seat in recent times as Artificial Intelligence has led scientists to advance Neuromorphic Computing to excel in the field of technology.


One of the technological advancements that has rekindled the interest of scientists in neuromorphic computing is the development of the Artificial Neural Network model (ANN).
Since traditional computers, backed by CPUs (Computer Processing Units) do not have the ability to support neuromorphic computing, modern computers are now being built with adequate hardware to support such technology.
Backed by the advanced technology of neuromorphic computing, computers can now act and work like the human brain. With the help of algorithms and data, neuromorphic computing enables computers to work rapidly and on low energy too.
Debussy - Claire De Lune
While the definition of this concept can be a bit too complicated to understand, the working of neuromorphic computing can make you understand the essence of it more easily. The working of neuromorphic computing-enabled devices begins with the placement of Artificial Neural Networks (ANN) that comprise millions of artificial neurons. These neurons are similar to the human brain neurons.
Enabling a machine (computer) to act and work like the human brain, layers of these artificial neurons pass signals to one another. These electric signals or electric spikes convert input into an output that results in the working of neuromorphic computing machines.
Beethoven - Symphony 5 (Allegro Con Brio)


The passing on of electric spikes or signals functions on the basis of Spiking Neural Networks (SNN). This spiking neural network architecture further enables an artificial machine to work like the human brain does and perform functions that humans can do on a daily basis.
This can involve visual recognition, interpretation of data, and a lot more such tasks. Since these artificial neurons only consume power when the electric spikes are passed through them, neuromorphic computing machines are low-power-consuming computers as compared to traditional computers.
By imitating the neuro-biological networks present in the human brain, neuromorphic computing machines work like a human brain and perform tasks efficiently and effectively. Bringing on the ability to work like the human brain, neuromorphic computing has advanced the developments in the field of technology. The engineering of computers in the earlier times led to the generation of traditional computers that consumed a lot of space for functioning.
However, computers working on the basis of neuromorphic computing consume much less space with an in-built capability to work faster and better.
Wagner - Ride of the Valkyries.
Features of Neuromorphic Computing
-
Rapid Response System
Neuromorphic computers are specifically known for their rapid response system because their processing is highly rapid. As compared to traditional computers, neuromorphic computers are built to work like a human brain and so their rapid response system is a major highlight.
-
Low Consumption of Power
Owing to the concept of Spiking Neural Networks (SNN), neuromorphic machines work when electric spikes or signals are passed through the artificial neurons. These artificial neurons work only when electric spikes are passed through them thus consuming low energy.
-
Higher Adaptability
Modern computers have a knack for adaptability and so do neuromorphic computers. With higher adaptability, neuromorphic computers work well according to the evolving demands of technology. With changing times, neuromorphic computers adapt themselves and change from time to time resulting in efficient working.
-
Fast-paced Learning
Machines working on the principle of neuromorphic computing are highly fast-paced when it comes to learning. Establishing algorithms based on interpretation of data and formulating algorithms as and when new data is fed into such computers, neuromorphic computing enables machines to learn rapidly.
-
Mobile Architecture
One of the most striking features of neuromorphic computing is its mobile architecture. Unlike traditional computers that used to consume vast space for working, neuromorphic computers are mobile and handy. They do not require much space and are highly efficient in terms of space occupancy.


Significance of Neuromorphic Computing
An essential realm of AI, neuromorphic AI computing is significant because of its advanced technology. Leading to the functioning of artificial computers like the human brain, neuromorphic computing has opened the doors to better technology and rapid growth in computer engineering.
Not only does it lead to rapid growth but neuromorphic computing chips have also revolutionized the way computers work. From the analysis of data to machine learning algorithms, computers can do almost anything today.
While neuromorphic computing was a concept introduced in the 1980s, it has only been brought into the limelight in recent times. With numerous neuromorphic computing applications in physics, data analytics, and numerical algorithms, the significance of this concept is unmatched.
Even though the concept has many challenges to face, it still is leading the revolution of making computers work along the lines of the human brain. We’ve seen a lot of progress in scaling and industrialization of neuromorphic architectures. Still, building and deploying complete neuromorphic solutions will require overcoming some additional challenges.
Can The Circle Be Unbroken (Bye & Bye) - Carter Family
Neuromorphic Computing and Artificial Intelligence
Artificial Intelligence technology intends to impart human abilities in computers to make them work like humans. On the other hand, neuromorphic computing attempts to engineer computers that work like the human brain does. Comprising millions of artificial neurons that pass on electric signals to one another, neuromorphic computing has been a revolutionary concept in the realm of Artificial Intelligence.
By inducing the technology of information processing, neuromorphic computers have become the leaders of AI that, as many say, have resulted in the 3rd wave. The third generation of AI has led scientists to draw parallels with the human brain and its abilities like the interpretation of data and adaptation.
With the help of one of the techniques of AI, (machine learning), neuromorphic computing has advanced the process of information processing and enabled computers to work with better and bigger technology. While the traditional computer software could only support Artificial Intelligence to a limited extent, modern age computers have come up to be faster, better, and brighter in terms of use and ability.
Thanks to AI, neuromorphic computing has reinvented its place in the field of technology and is pushing the limits of AI further. Intertwined with each other, neuromorphic computing and AI have a long way to go as both attempt to mimic human abilities and imitate them in computer software.


Future of Neuromorphic Computing
In simple terms, Artificial Intelligence future is Neuromorphic Computing. Setting forth the third wave or era of AI, neuromorphic computing will take over the technological advancements of the field and become the driving force of artificial intelligence future scope.
While the current wave of AI is faced with a number of challenges like heavy processing hardware and software storage capacity, the third wave of neuromorphic computing in AI will most likely put a stop to these challenges and enable the human-like activities performed by computers.
Strauss - The Blue Danube
Neuromorphic chips, being manufactured by big tech giants like Intel andIBM, will be the key factor in making computers function like the human nervous system. "The neuromorphic computing market is poised to grow rapidly over the next decade to reach approximately $1.78 billion by 2025. This is the result of the growing interest of companies in Artificial Intelligence which can always do with more and more computing power.
Born To Survive


Neuromorphic computing will bring forth the untouched capabilities of AI and will set a revolutionary example in the coming years.
The objective of neuromorphic computing is to make computers behave like a human brain and work along the lines of the human nervous system, and neuromorphic computing posits the engineering of computers in a way that comprises millions of artificial silicon neurons enabled to transfer electric spikes from one another.
Moonlight” Sonata

2001 Space Odyssey
Artificial intelligence generally falls under two broad categories:
- Narrow AI: Sometimes referred to as "Weak AI," this kind of artificial intelligence operates within a limited context and is a simulation of human intelligence. Narrow AI is often focused on performing a single task extremely well and while these machines may seem intelligent, they are operating under far more constraints and limitations than even the most basic human intelligence.
- Artificial General Intelligence (AGI): AGI, sometimes referred to as "Strong AI," is the kind of artificial intelligence we see in the movies, like the robots from Westworld or Data from Star Trek: The Next Generation. AGI is a machine with general intelligence and, much like a human being, it can apply that intelligence to solve any problem.
Narrow AI is all around us and is easily the most successful realization of artificial intelligence to date. With its focus on performing specific tasks, Narrow AI has experienced numerous breakthroughs in the last decade. Some examples of narrow AI include Google Search and Image recognition.
Much of Narrow AI is powered by breakthroughs in machine learning and deep learning. Artificial intelligence is a set of algorithms and intelligence to try to mimic human intelligence. Machine learning is one of them, and deep learning is one of those machine learning techniques.
Machine learning feeds a computer data and uses statistical techniques to help it learn how to get progressively better at a task, without having been specifically programmed for that task, eliminating the need for millions of lines of written code. Machine learning consists of both supervised learning (using labeled data sets) and unsupervised learning (using unlabeled data sets).
Deep learning is a type of machine learning that runs inputs through a biologically-inspired neural network architecture. The neural networks contain a number of hidden layers through which the data is processed, allowing the machine to go "deep" in its learning, making connections and weighting input for the best results. The creation of a machine with human-level intelligence that can be applied to any task is the Holy Grail for many AI researchers, but the quest for AGI has not yet been developed. A universal algorithm for learning and acting in any environment would be essentially creating a machine with a full set of cognitive abilities.

Machine Learning
A computer “learns” when its software is able to successfully predict and react to unfolding scenarios based on previous outcomes. Machine learning refers to the process by which computers develop pattern recognition, or the ability to continuously learn from and make predictions based on data, and can make adjustments without being specifically programmed to do so. A form of artificial intelligence, machine learning effectively automates the process of analytical model-building and allows machines to adapt to new scenarios independently.
Four steps for building a machine learning model.
1. Select and prepare a training data set necessary to solving the problem. This data can be labeled or unlabeled.
2. Choose an algorithm to run on the training data.
- If the data is labeled, the algorithm could be regression, decision trees, or instance-based.
- If the data is unlabeled, the algorithm could be a clustering algorithm, an association algorithm, or a neural network.
- Train the algorithm to create the model.
4. Use and improve the model.
There are three methods of machine learning: “Supervised” learning works with labeled data and requires less training. “Unsupervised” learning is used to classify unlabeled data by identifying patterns and relationships. “Semi-supervised” learning uses a small labeled data set to guide classification of a larger unlabeled data set.

Bizet - Carmen Suite 2 (Habanera)
AI has the unique ability to extract meaning from data when you can define what the answer looks like but not how to get there. AI can amplify human capabilities and turn exponentially growing data into insight, action, and value.
Today, AI is used in a variety of applications across industries, including healthcare, manufacturing, and government. Here are a few specific use cases:
- Prescriptive maintenance and quality control improves production, manufacturing, and retail through an open framework for IT/ OT. Integrated solutions prescribe best maintenance decisions, automate actions, and enhance quality control processes by implementing enterprise AI-based computer vision techniques.
- Speech and language processing transforms unstructured audio data into insight and intelligence. It automates the understanding of spoken and written language with machines using natural language processing, speech-to-text analytics, biometric search, or live call monitoring.
- Video analytics and surveillance automatically analyzes video to detect events, uncover identity, environment, and people, and obtain operational insights. It uses edge-to-core video analytics systems for a wide variety of workload and operating conditions.
- Highly autonomous driving is built on a scale-out data ingestion platform to enable developers to build the optimum highly-autonomous driving solution tuned for open source services, machine learning, and deep learning neural networks.
Unlocking the power of AI is best to map out the enterprise path forward to meet near and longer-term objectives. The objective is to unlock the value of data across the enterprise to empower business transformation and growth.
- End-to-end solutions to reduce complexity and support integration with existing infrastructure
- On-prem, cloud, and hybrid options that take into account team location, access needs, security, and cost constraints
- Systems that scale for current and future needs
Deep Learning
Deep learning is a subset of machine learning that has demonstrated significantly superior performance to some traditional machine learning approaches. Deep learning utilizes a combination of multi-layer artificial neural networks and data- and compute-intensive training, inspired by our latest understanding of human brain behavior. This approach has become so effective it’s even begun to surpass human abilities in many areas, such as image and speech recognition and natural language processing.
Deep learning models process large amounts of data and are typically unsupervised or semi-supervised. Recent advances in algorithms, the proliferation of digital data sets, and improvements in computing—including increases in processing power and decreases in price—have come together to initiate a new breed of AI technology that is enterprise-ready. Nearly all organizations have an ever-growing mountain of data assets, and AI provides the means to analyze this resource at scale.
AI is also set to become an enterprise staple as a cornerstone in the digital transformation process. AI is an omni-use technology that can optimize efficiency and insight in almost any business process—from customer service operations and physical and cybersecurity systems to R&D functions and business analytics processes.

Examples of AI
Examples of AI are incorporated into a variety of different types of technology illustrates it enormous benefits.
- Automation. When paired with AI technologies, automation tools can expand the volume and types of tasks performed. An example is robotic process automation (RPA), a type of software that automates repetitive, rules-based data processing tasks traditionally done by humans. When combined with machine learning and emerging AI tools, RPA can automate bigger portions of enterprise jobs, enabling RPA's tactical bots to pass along intelligence from AI and respond to process changes.
- Machine learning. This is the science of getting a computer to act without programming. Deep learning is a subset of machine learning that, in very simple terms, can be thought of as the automation of predictive analytics. There are three types of machine learning algorithms:
- Supervised learning. Data sets are labeled so that patterns can be detected and used to label new data sets.
- Unsupervised learning. Data sets aren't labeled and are sorted according to similarities or differences.
- Reinforcement learning. Data sets aren't labeled but, after performing an action or several actions, the AI system is given feedback.
- Machine vision. This technology gives a machine the ability to see. Machine vision captures and analyzes visual information using a camera, analog-to-digital conversion and digital signal processing. It is often compared to human eyesight, but machine vision isn't bound by biology and can be programmed to see through walls, for example. It is used in a range of applications from signature identification to medical image analysis. Computer vision, which is focused on machine-based image processing, is often conflated with machine vision.
- Natural language processing (NLP). This is the processing of human language by a computer program. One of the older and best-known examples of NLP is spam detection, which looks at the subject line and text of an email and decides if it's junk. Current approaches to NLP are based on machine learning. NLP tasks include text translation, sentiment analysis and speech recognition.
- Robotics. This field of engineering focuses on the design and manufacturing of robots. Robots are often used to perform tasks that are difficult for humans to perform or perform consistently. For example, robots are used in assembly lines for car production or by NASA to move large objects in space. Researchers are also using machine learning to build robots that can interact in social settings.
- Self-driving cars. Autonomous vehicles use a combination of computer vision, image recognition and deep learning to build automated skill at piloting a vehicle while staying in a given lane and avoiding unexpected obstructions, such as pedestrians.
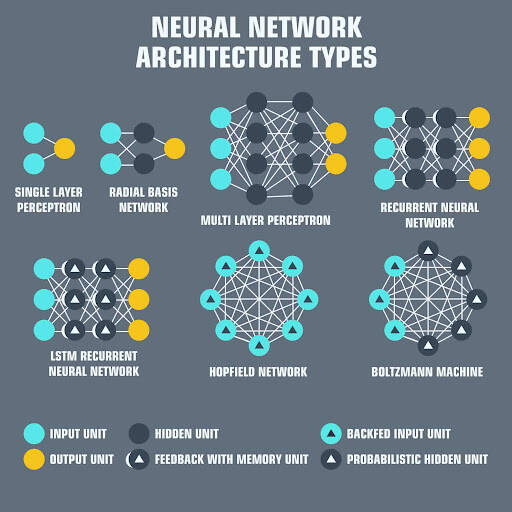
There are many different types of neural networks used for AI. The problem with drawing them as node maps is that it doesn’t really show how they’re used. For example, variational autoencoders (VAE) may look just like autoencoders (AE), but the training process is actually quite different. The use-cases for trained networks differ even more, because VAEs are generators, where you insert noise to get a new sample. AEs, simply map whatever they get as input to the closest training sample they “remember”. I should add that this overview is in no way clarifying how each of the different node types work internally (but that’s a topic for another day).
It should be noted that while most of the abbreviations used are generally accepted, not all of them are. RNNs sometimes refer to recursive neural networks, but most of the time they refer to recurrent neural networks. That’s not the end of it though, in many places you’ll find RNN used as placeholder for any recurrent architecture, including LSTMs, GRUs and even the bidirectional variants. AEs suffer from a similar problem from time to time, where VAEs and DAEs and the like are called simply AEs. Many abbreviations also vary in the amount of “N”s to add at the end, because you could call it a convolutional neural network but also simply a convolutional network (resulting in CNN or CN).
Composing a complete list is practically impossible, as new architectures are invented all the time. While the list of neural networks may provide you with some insights into the world of AI, but this list is not comprehensive.
For each of the architectures depicted in the picture, brief description is provided..


Feed forward neural networks (FF or FFNN) and perceptrons (P) are very straight forward, they feed information from the front to the back (input and output, respectively). Neural networks are often described as having layers, where each layer consists of either input, hidden or output cells in parallel. A layer alone never has connections and in general two adjacent layers are fully connected (every neuron form one layer to every neuron to another layer). The simplest somewhat practical network has two input cells and one output cell, which can be used to model logic gates. One usually trains FFNNs through back-propagation, giving the network paired datasets of “what goes in” and “what we want to have coming out”. This is called supervised learning, as opposed to unsupervised learning where we only give it input and let the network fill in the blanks. The error being back-propagated is often some variation of the difference between the input and the output (like MSE or just the linear difference). Given that the network has enough hidden neurons, it can theoretically always model the relationship between the input and output. Practically their use is a lot more limited but they are popularly combined with other networks to form new networks.
Radial basis function (RBF) networks are FFNNs with radial basis functions as activation functions. There’s nothing more to it. Doesn’t mean they don’t have their uses, but most FFNNs with other activation functions don’t get their own name. This mostly has to do with inventing them at the right time.
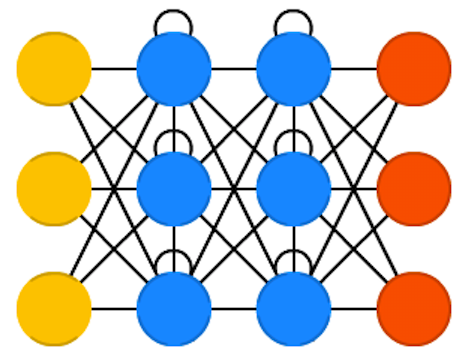
Recurrent neural networks (RNN) are FFNNs with a time twist: they are not stateless; they have connections between passes, connections through time. Neurons are fed information not just from the previous layer but also from themselves from the previous pass. This means that the order in which you feed the input and train the network matters: feeding it “milk” and then “cookies” may yield different results compared to feeding it “cookies” and then “milk”. One big problem with RNNs is the vanishing (or exploding) gradient problem where, depending on the activation functions used, information rapidly gets lost over time, just like very deep FFNNs lose information in depth. Intuitively this wouldn’t be much of a problem because these are just weights and not neuron states, but the weights through time is actually where the information from the past is stored; if the weight reaches a value of 0 or 1 000 000, the previous state won’t be very informative. RNNs can in principle be used in many fields as most forms of data that don’t actually have a timeline (i.e. unlike sound or video) can be represented as a sequence. A picture or a string of text can be fed one pixel or character at a time, so the time dependent weights are used for what came before in the sequence, not actually from what happened x seconds before. In general, recurrent networks are a good choice for advancing or completing information, such as autocompletion.
Long / short term memory (LSTM) networks try to combat the vanishing / exploding gradient problem by introducing gates and an explicitly defined memory cell. These are inspired mostly by circuitry, not so much biology. Each neuron has a memory cell and three gates: input, output and forget. The function of these gates is to safeguard the information by stopping or allowing the flow of it. The input gate determines how much of the information from the previous layer gets stored in the cell. The output layer takes the job on the other end and determines how much of the next layer gets to know about the state of this cell. The forget gate seems like an odd inclusion at first but sometimes it’s good to forget: if it’s learning a book and a new chapter begins, it may be necessary for the network to forget some characters from the previous chapter. LSTMs have been shown to be able to learn complex sequences, such as writing like Shakespeare or composing primitive music. Note that each of these gates has a weight to a cell in the previous neuron, so they typically require more resources to run.

Gated recurrent units (GRU) are a slight variation on LSTMs. They have one less gate and are wired slightly differently: instead of an input, output and a forget gate, they have an update gate. This update gate determines both how much information to keep from the last state and how much information to let in from the previous layer. The reset gate functions much like the forget gate of an LSTM but it’s located slightly differently. They always send out their full state, they don’t have an output gate. In most cases, they function very similarly to LSTMs, with the biggest difference being that GRUs are slightly faster and easier to run (but also slightly less expressive). In practice these tend to cancel each other out, as you need a bigger network to regain some expressiveness which then in turn cancels out the performance benefits. In some cases where the extra expressiveness is not needed, GRUs can outperform LSTMs.
Bidirectional recurrent neural networks, bidirectional long / short term memory networks and bidirectional gated recurrent units (BiRNN, BiLSTM and BiGRU respectively) are not shown on the chart because they look exactly the same as their unidirectional counterparts. The difference is that these networks are not just connected to the past, but also to the future. As an example, unidirectional LSTMs might be trained to predict the word “fish” by being fed the letters one by one, where the recurrent connections through time remember the last value. A BiLSTM would also be fed the next letter in the sequence on the backward pass, giving it access to future information. This trains the network to fill in gaps instead of advancing information, so instead of expanding an image on the edge, it could fill a hole in the middle of an image.
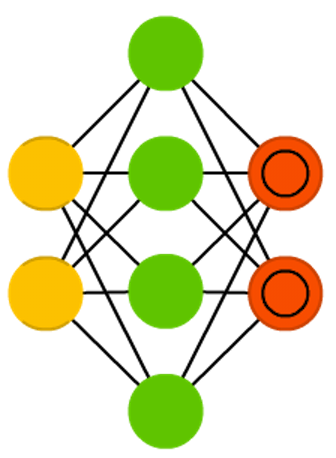
Autoencoders (AE) are somewhat similar to FFNNs as AEs are more like a different use of FFNNs than a fundamentally different architecture. The basic idea behind autoencoders is to encode information (as in compress, not encrypt) automatically, hence the name. The entire network always resembles an hourglass like shape, with smaller hidden layers than the input and output layers. AEs are also always symmetrical around the middle layer(s) (one or two depending on an even or odd amount of layers). The smallest layer(s) is|are almost always in the middle, the place where the information is most compressed (the chokepoint of the network). Everything up to the middle is called the encoding part, everything after the middle the decoding and the middle (surprise) the code. One can train them using backpropagation by feeding input and setting the error to be the difference between the input and what came out. AEs can be built symmetrically when it comes to weights as well, so the encoding weights are the same as the decoding weights.

Variational autoencoders (VAE) have the same architecture as AEs but are “taught” something else: an approximated probability distribution of the input samples. It’s a bit back to the roots as they are bit more closely related to BMs and RBMs. They do however rely on Bayesian mathematics regarding probabilistic inference and independence, as well as a re-parametrisation trick to achieve this different representation. The inference and independence parts make sense intuitively, but they rely on somewhat complex mathematics. The basics come down to this: take influence into account. If one thing happens in one place and something else happens somewhere else, they are not necessarily related. If they are not related, then the error propagation should consider that. This is a useful approach because neural networks are large graphs (in a way), so it helps if you can rule out influence from some nodes to other nodes as you dive into deeper layers.
Denoising autoencoders (DAE) are AEs where we don’t feed just the input data, but we feed the input data with noise (like making an image more grainy). We compute the error the same way though, so the output of the network is compared to the original input without noise. This encourages the network not to learn details but broader features, as learning smaller features often turns out to be “wrong” due to it constantly changing with noise.
Sparse autoencoders (SAE) are in a way the opposite of AEs. Instead of teaching a network to represent a bunch of information in less “space” or nodes, we try to encode information in more space. So instead of the network converging in the middle and then expanding back to the input size, we blow up the middle. These types of networks can be used to extract many small features from a dataset. If one were to train a SAE the same way as an AE, you would in almost all cases end up with a pretty useless identity network (as in what comes in is what comes out, without any transformation or decomposition). To prevent this, instead of feeding back the input, we feed back the input plus a sparsity driver. This sparsity driver can take the form of a threshold filter, where only a certain error is passed back and trained, the other error will be “irrelevant” for that pass and set to zero. In a way this resembles spiking neural networks, where not all neurons fire all the time (and points are scored for biological plausibility).
Markov chains (MC or discrete time Markov Chain, DTMC) are kind of the predecessors to BMs and HNs. They can be understood as follows: from this node where I am now, what are the odds of me going to any of my neighbouring nodes? They are memoryless (i.e. Markov Property) which means that every state you end up in depends completely on the previous state. While not really a neural network, they do resemble neural networks and form the theoretical basis for BMs and HNs. MC aren’t always considered neural networks, as goes for BMs, RBMs and HNs. Markov chains aren’t always fully connected either.
A Hopfield network (HN) is a network where every neuron is connected to every other neuron; it is a completely entangled plate of spaghetti as even all the nodes function as everything. Each node is input before training, then hidden during training and output afterwards. The networks are trained by setting the value of the neurons to the desired pattern after which the weights can be computed. The weights do not change after this. Once trained for one or more patterns, the network will always converge to one of the learned patterns because the network is only stable in those states. Note that it does not always conform to the desired state (it’s not a magic black box sadly). It stabilises in part due to the total “energy” or “temperature” of the network being reduced incrementally during training. Each neuron has an activation threshold which scales to this temperature, which if surpassed by summing the input causes the neuron to take the form of one of two states (usually -1 or 1, sometimes 0 or 1). Updating the network can be done synchronously or more commonly one by one. If updated one by one, a fair random sequence is created to organise which cells update in what order (fair random being all options (n) occurring exactly once every n items). This is so you can tell when the network is stable (done converging), once every cell has been updated and none of them changed, the network is stable (annealed). These networks are often called associative memory because the converge to the most similar state as the input; if humans see half a table we can image the other half, this network will converge to a table if presented with half noise and half a table.


Boltzmann machines (BM) are a lot like HNs, but: some neurons are marked as input neurons and others remain “hidden”. The input neurons become output neurons at the end of a full network update. It starts with random weights and learns through back-propagation, or more recently through contrastive divergence (a Markov chain is used to determine the gradients between two informational gains). Compared to a HN, the neurons mostly have binary activation patterns. As hinted by being trained by MCs, BMs are stochastic networks. The training and running process of a BM is fairly similar to a HN: one sets the input neurons to certain clamped values after which the network is set free (it doesn’t get a sock). While free the cells can get any value and we repetitively go back and forth between the input and hidden neurons. The activation is controlled by a global temperature value, which if lowered lowers the energy of the cells. This lower energy causes their activation patterns to stabilise. The network reaches an equilibrium given the right temperature.
Restricted Boltzmann machines (RBM) are remarkably similar to BMs (surprise) and therefore also similar to HNs. The biggest difference between BMs and RBMs is that RBMs are a better usable because they are more restricted. They don’t trigger-happily connect every neuron to every other neuron but only connect every different group of neurons to every other group, so no input neurons are directly connected to other input neurons and no hidden to hidden connections are made either. RBMs can be trained like FFNNs with a twist: instead of passing data forward and then back-propagating, you forward pass the data and then backward pass the data (back to the first layer). After that you train with forward-and-back-propagation.

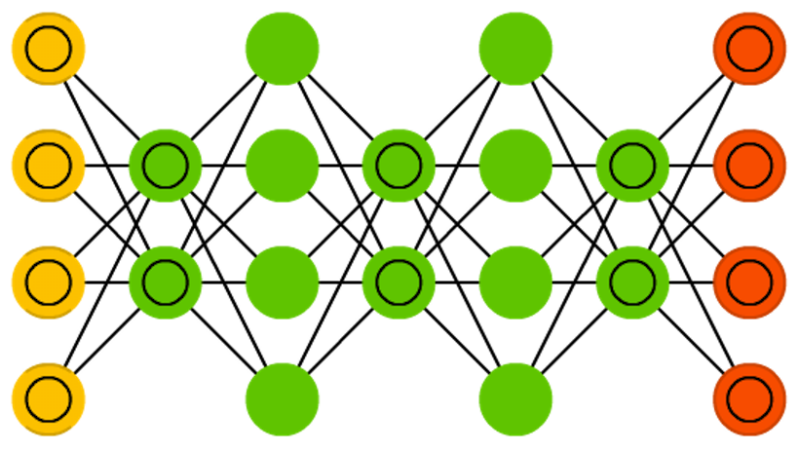
Deep belief networks (DBN) is the name given to stacked architectures of mostly RBMs or VAEs. These networks have been shown to be effectively trainable stack by stack, where each AE or RBM only has to learn to encode the previous network. This technique is also known as greedy training, where greedy means making locally optimal solutions to get to a decent but possibly not optimal answer. DBNs can be trained through contrastive divergence or back-propagation and learn to represent the data as a probabilistic model, just like regular RBMs or VAEs. Once trained or converged to a (more) stable state through unsupervised learning, the model can be used to generate new data. If trained with contrastive divergence, it can even classify existing data because the neurons have been taught to look for different features.
Convolutional neural networks (CNN or deep convolutional neural networks, DCNN) are quite different from most other networks. They are primarily used for image processing but can also be used for other types of input such as as audio. A typical use case for CNNs is where you feed the network images and the network classifies the data, e.g. it outputs “cat” if you give it a cat picture and “dog” when you give it a dog picture. CNNs tend to start with an input “scanner” which is not intended to parse all the training data at once. For example, to input an image of 200 x 200 pixels, you wouldn’t want a layer with 40 000 nodes. Rather, you create a scanning input layer of say 20 x 20 which you feed the first 20 x 20 pixels of the image (usually starting in the upper left corner). Once you passed that input (and possibly use it for training) you feed it the next 20 x 20 pixels: you move the scanner one pixel to the right. Note that one wouldn’t move the input 20 pixels (or whatever scanner width) over, you’re not dissecting the image into blocks of 20 x 20, but rather you’re crawling over it. This input data is then fed through convolutional layers instead of normal layers, where not all nodes are connected to all nodes. Each node only concerns itself with close neighbouring cells (how close depends on the implementation, but usually not more than a few). These convolutional layers also tend to shrink as they become deeper, mostly by easily divisible factors of the input (so 20 would probably go to a layer of 10 followed by a layer of 5). Powers of two are very commonly used here, as they can be divided cleanly and completely by definition: 32, 16, 8, 4, 2, 1. Besides these convolutional layers, they also often feature pooling layers. Pooling is a way to filter out details: a commonly found pooling technique is max pooling, where we take say 2 x 2 pixels and pass on the pixel with the most amount of red. To apply CNNs for audio, you basically feed the input audio waves and inch over the length of the clip, segment by segment. Real world implementations of CNNs often glue an FFNN to the end to further process the data, which allows for highly non-linear abstractions. These networks are called DCNNs but the names and abbreviations between these two are often used interchangeably.
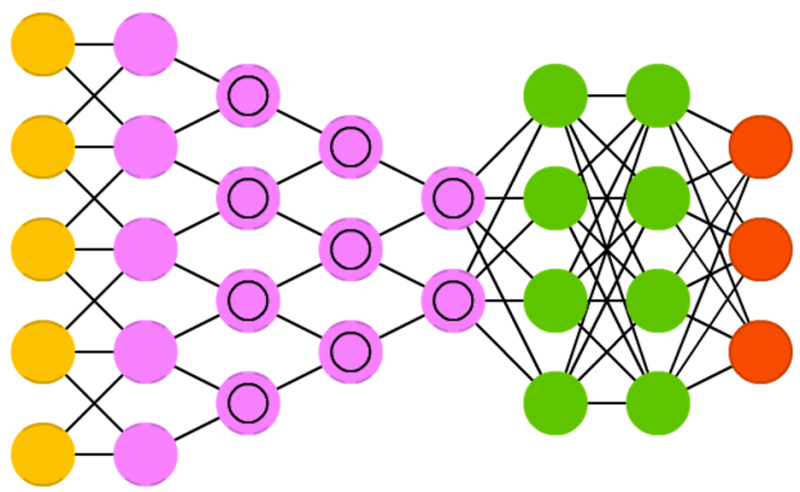

Deconvolutional networks (DN), also called inverse graphics networks (IGNs), are reversed convolutional neural networks. Imagine feeding a network the word “cat” and training it to produce cat-like pictures, by comparing what it generates to real pictures of cats. DNNs can be combined with FFNNs just like regular CNNs, but this is about the point where the line is drawn with coming up with new abbreviations. They may be referenced as deep deconvolutional neural networks, but you could argue that when you stick FFNNs to the back and the front of DNNs that you have yet another architecture which deserves a new name. Note that in most applications one wouldn’t actually feed text-like input to the network, more likely a binary classification input vector. Think <0, 1> being cat, <1, 0> being dog and <1, 1> being cat and dog. The pooling layers commonly found in CNNs are often replaced with similar inverse operations, mainly interpolation and extrapolation with biased assumptions (if a pooling layer uses max pooling, you can invent exclusively lower new data when reversing it).
Deep convolutional inverse graphics networks (DCIGN) have a somewhat misleading name, as they are actually VAEs but with CNNs and DNNs for the respective encoders and decoders. These networks attempt to model “features” in the encoding as probabilities, so that it can learn to produce a picture with a cat and a dog together, having only ever seen one of the two in separate pictures. Similarly, you could feed it a picture of a cat with your neighbours’ annoying dog on it, and ask it to remove the dog, without ever having done such an operation. Demo’s have shown that these networks can also learn to model complex transformations on images, such as changing the source of light or the rotation of a 3D object. These networks tend to be trained with back-propagation.

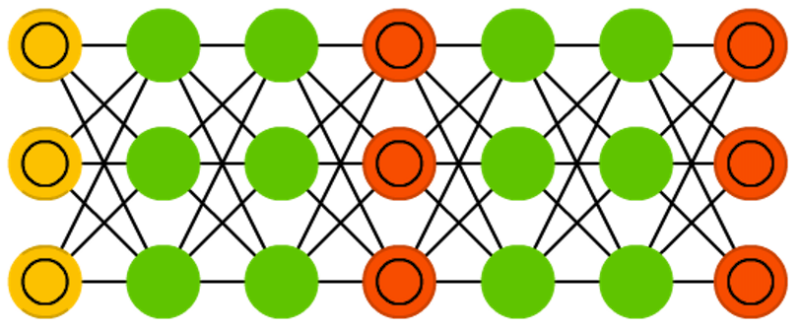
Generative adversarial networks (GAN) are from a different breed of networks, they are twins: two networks working together. GANs consist of any two networks (although often a combination of FFs and CNNs), with one tasked to generate content and the other has to judge content. The discriminating network receives either training data or generated content from the generative network. How well the discriminating network was able to correctly predict the data source is then used as part of the error for the generating network. This creates a form of competition where the discriminator is getting better at distinguishing real data from generated data and the generator is learning to become less predictable to the discriminator. This works well in part because even quite complex noise-like patterns are eventually predictable but generated content similar in features to the input data is harder to learn to distinguish. GANs can be quite difficult to train, as you don’t just have to train two networks (either of which can pose it’s own problems) but their dynamics need to be balanced as well. If prediction or generation becomes to good compared to the other, a GAN won’t converge as there is intrinsic divergence.
Liquid state machines (LSM) are similar soups, looking a lot like ESNs. The real difference is that LSMs are a type of spiking neural networks: sigmoid activations are replaced with threshold functions and each neuron is also an accumulating memory cell. So when updating a neuron, the value is not set to the sum of the neighbours, but rather added to itself. Once the threshold is reached, it releases its’ energy to other neurons. This creates a spiking like pattern, where nothing happens for a while until a threshold is suddenly reached.

Extreme learning machines (ELM) are basically FFNNs but with random connections. They look very similar to LSMs and ESNs, but they are not recurrent nor spiking. They also do not use backpropagation. Instead, they start with random weights and train the weights in a single step according to the least-squares fit (lowest error across all functions). This results in a much less expressive network but it’s also much faster than backpropagation.
Echo state networks (ESN) are yet another different type of (recurrent) network. This one sets itself apart from others by having random connections between the neurons (i.e. not organised into neat sets of layers), and they are trained differently. Instead of feeding input and back-propagating the error, we feed the input, forward it and update the neurons for a while, and observe the output over time. The input and the output layers have a slightly unconventional role as the input layer is used to prime the network and the output layer acts as an observer of the activation patterns that unfold over time. During training, only the connections between the observer and the (soup of) hidden units are changed.
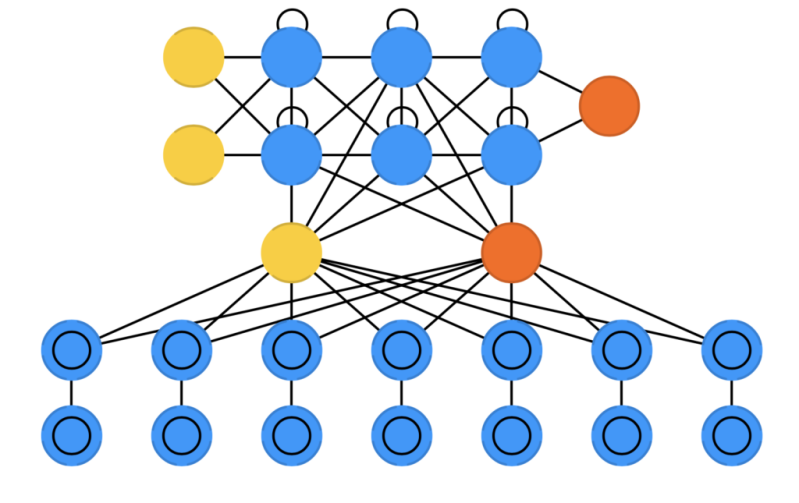
Differentiable Neural Computers (DNC) are enhanced Neural Turing Machines with scalable memory, inspired by how memories are stored by the human hippocampus. The idea is to take the classical Von Neumann computer architecture and replace the CPU with an RNN, which learns when and what to read from the RAM. Besides having a large bank of numbers as memory (which may be resized without retraining the RNN). The DNC also has three attention mechanisms. These mechanisms allow the RNN to query the similarity of a bit of input to the memory’s entries, the temporal relationship between any two entries in memory, and whether a memory entry was recently updated – which makes it less likely to be overwritten when there’s no empty memory available.
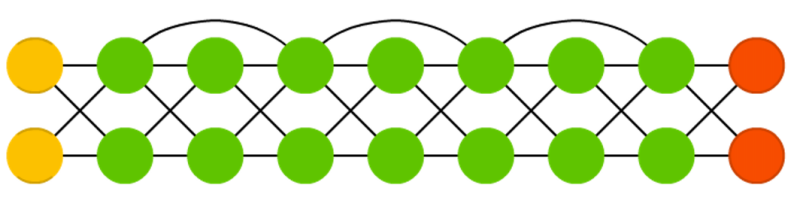
Deep residual networks (DRN) are very deep FFNNs with extra connections passing input from one layer to a later layer (often 2 to 5 layers) as well as the next layer. Instead of trying to find a solution for mapping some input to some output across say 5 layers, the network is enforced to learn to map some input to some output + some input. Basically, it adds an identity to the solution, carrying the older input over and serving it freshly to a later layer. It has been shown that these networks are very effective at learning patterns up to 150 layers deep, much more than the regular 2 to 5 layers one could expect to train. However, it has been proven that these networks are in essence just RNNs without the explicit time based construction and they’re often compared to LSTMs without gates.
Neural Turing machines (NTM) can be understood as an abstraction of LSTMs and an attempt to un-black-box neural networks (and give us some insight in what is going on in there). Instead of coding a memory cell directly into a neuron, the memory is separated. It’s an attempt to combine the efficiency and permanency of regular digital storage and the efficiency and expressive power of neural networks. The idea is to have a content-addressable memory bank and a neural network that can read and write from it. The “Turing” in Neural Turing Machines comes from them being Turing complete: the ability to read and write and change state based on what it reads means it can represent anything a Universal Turing Machine can represent.
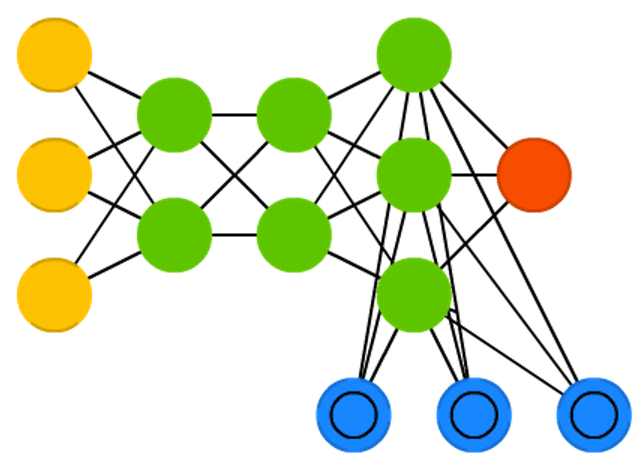
Capsule Networks (CapsNet) are biology inspired alternatives to pooling, where neurons are connected with multiple weights (a vector) instead of just one weight (a scalar). This allows neurons to transfer more information than simply which feature was detected, such as where a feature is in the picture or what colour and orientation it has. The learning process involves a local form of Hebbian learning that values correct predictions of output in the next layer.

Kohonen networks (KN, also self organising (feature) map, SOM, SOFM) utilise competitive learning to classify data without supervision. Input is presented to the network, after which the network assesses which of its neurons most closely match that input. These neurons are then adjusted to match the input even better, dragging along their neighbours in the process. How much the neighbours are moved depends on the distance of the neighbours to the best matching units.
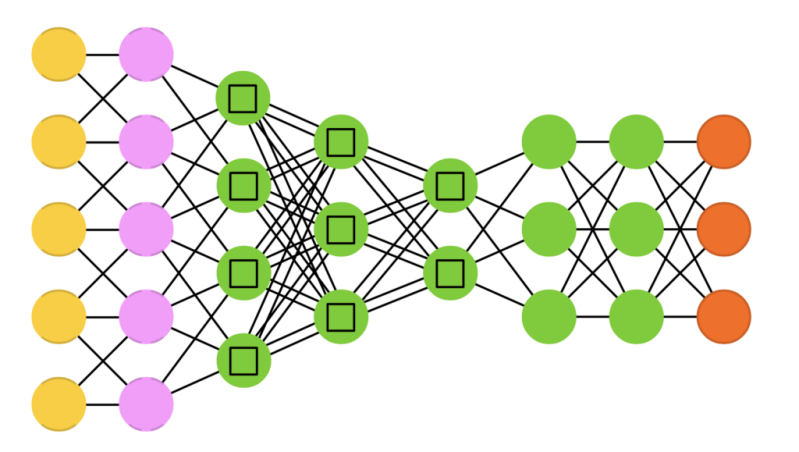
Attention networks (AN) can be considered a class of networks, which includes the Transformer architecture. They use an attention mechanism to combat information decay by separately storing previous network states and switching attention between the states. The hidden states of each iteration in the encoding layers are stored in memory cells. The decoding layers are connected to the encoding layers, but it also receives data from the memory cells filtered by an attention context. This filtering step adds context for the decoding layers stressing the importance of particular features. The attention network producing this context is trained using the error signal from the output of decoding layer. Moreover, the attention context can be visualized giving valuable insight into which input features correspond with what output features.
A neural network is an interconnected group of nodes, akin to the vast network of neurons in the human brain.
Neural networks were inspired by the architecture of neurons in the human brain. A simple "neuron" N accepts input from other neurons, each of which, when activated (or "fired"), casts a weighted "vote" for or against whether neuron N should itself activate. Learning requires an algorithm to adjust these weights based on the training data; one simple algorithm (dubbed "fire together, wire together") is to increase the weight between two connected neurons when the activation of one triggers the successful activation of another. Neurons have a continuous spectrum of activation; in addition, neurons can process inputs in a nonlinear way rather than weighing straightforward votes.
Modern neural networks model complex relationships between inputs and outputs or and find patterns in data. They can learn continuous functions and even digital logical operations. Neural networks can be viewed a type of mathematical optimization — they perform a gradient descent on a multi-dimensional topology that was created by training the network. The most common training technique is the backpropagation algorithm. Other learning techniques for neural networks are Hebbian learning ("fire together, wire together"), GMDH or competitive learning.
The main categories of networks are acyclic or feedforward neural networks (where the signal passes in only one direction) and recurrent neural networks (which allow feedback and short-term memories of previous input events). Among the most popular feedforward networks are perceptrons, multi-layer perceptrons and radial basis networks.
Deep learning is used to represent Images on Multiple Layers of Abstraction in Deep Learning
Deep learning uses several layers of neurons between the network's inputs and outputs. The multiple layers can progressively extract higher-level features from the raw input. For example, in image processing, lower layers may identify edges, while higher layers may identify the concepts relevant to a human such as digits or letters or faces. Deep learning has drastically improved the performance of programs in many important subfields of artificial intelligence, including computer vision, speech recognition, image classification and others.
Deep learning often uses convolutional neural networks for many or all of its layers. In a convolutional layer, each neuron receives input from only a restricted area of the previous layer called the neuron's receptive field. This can substantially reduce the number of weighted connections between neurons, and creates a hierarchy similar to the organization of the animal visual cortex.
In a recurrent neural network the signal will propagate through a layer more than once; thus, an RNN is an example of deep learning.[ RNNs can be trained by gradient descent, however long-term gradients which are back-propagated can "vanish" (that is, they can tend to zero) or "explode" (that is, they can tend to infinity), known as the vanishing gradient problem.[The long short term memory (LSTM) technique can prevent this in most cases.

Data Science
Data science uses scientific methods, processes, algorithms and systems to extract knowledge and insights from noisy, structured and unstructured data, and apply knowledge and actionable insights from data across a broad range of application domains.
Data science has a five-stage life cycle that require different techniques, programs and skill sets.
- Capture: Data acquisition, data entry, signal reception, data extraction
- Maintain: Data warehousing, data cleansing, data staging, data processing, data architecture
- Process: Data Mining, clustering/classification, data modeling, data summarization
- Communicate: Data reporting, data visualization, business intelligence, decision making
- Analyze: Exploratory/confirmatory, predictive analysis, regression, text mining, qualitative analysis
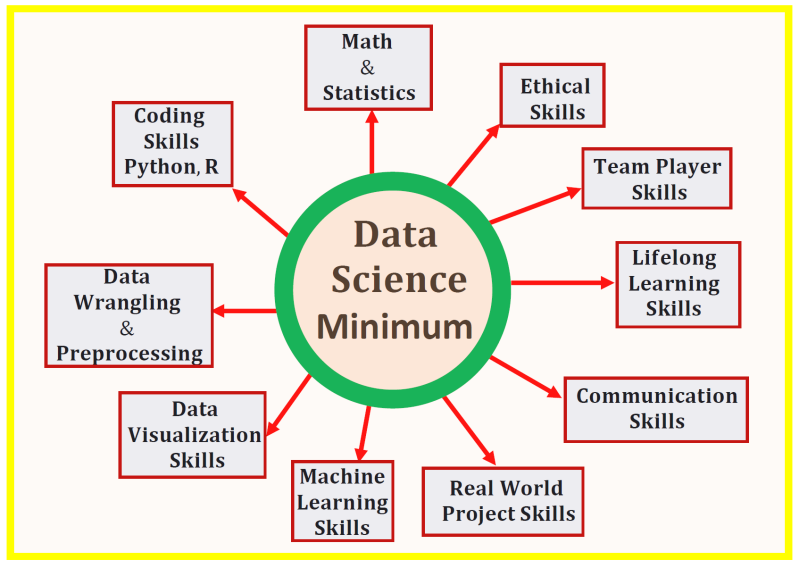
Data science involves a plethora of disciplines and expertise areas to produce a holistic, thorough and refined look into raw data. Data scientists must be skilled in everything from data engineering, math, statistics, advanced computing and visualizations to be able to effectively sift through muddled masses of information and communicate only the most vital bits that will help drive innovation and efficiency. Data science relies heavily on artificial intelligence, especially its subfields of machine learning and deep learning, to create models and make predictions using algorithms and other techniques.
Regression Trees are decision tree models are nested if-else conditions. Regression trees, a variant of decision trees, aim to predict outcomes we would consider real numbers such as the optimal prescription dosage, the cost of gas next year. This model can be viewed as a tree because regression models attempt to determine the relationship between one dependent variable and a series of independent variables that split off from the initial data set.
Data Transformation
Digital transformation allows business to connect with knowledge systems to improve customer satisfaction. The automation of knowledge management systems has proved to increase the growth of revenue by transforming customer engagement.

Intergration
Systems integration, is the connection of data, applications, APIs, and devices across the IT organization to be more efficient, productive, and agile. Integration connects and adds value through the new functionalities provided by connecting different systems' functions. APIs enable businesses to be more efficient, productive, and agile. Integration is critical to business transformation to allow everything in IT to work together. Integration not only connects, but it also adds value through the new functionalities provided by connecting different functions. For example, Apache Kafka is an open source platform that allows you to integrate streams of data with your applications, so they can act on data in real-time.
IT integration isn’t the same as continuous integration (CI), which is a developer practice where working copies of code are merged into a shared central repository multiple times a day. The goal of CI is to automate build and verifications so problems can be detected earlier—leading to faster development. IT systems have sprawled out over the organization away from one another. Since each vendor’s solutions do communicate between one another, the entire IT stack needs a way to organize this technology "spaghetti" and allow it to act on business logic.


Enterprise Application Integration (EAI) is the solution to this disparate sprawl. EAI technologies provide the tooling, and a framework that implements real-time, message-based integration between apps. These messages are triggered by changes or parameters built within the individual apps. EAI is deployed with point-to-point and hub-and-spoke architecture.
The point-to-point model enables each application to be customized to talk to the other applications and pieces of the IT. This must bel customized for each IT asset and for each asset that it connects. It is very difficult to use this model, because it is difficult to maintain as new applications are deployed.
The hub-and-spoke model, where the connections between apps and services are handled by a central broker knows as the hub. The spokes that connect the hub to the apps and services can be individually maintained. This allows the apps themselves to be more focused, with all arts of integrations handled via the hub and spokes. The main downside to this approach is the centralization of the hub. It becomes a single point of failure for the system and for your infrastructure communications. All integrations in the EAI hub-and-spoke model is designed to be dependent on the hub to function.
The centralization of the hub is the major weakness, since it becomes a single point of failure for the system and for the infrastructure communications. All integrations in the EAI hub-and-spoke model is designed to be dependent on the hub to function.
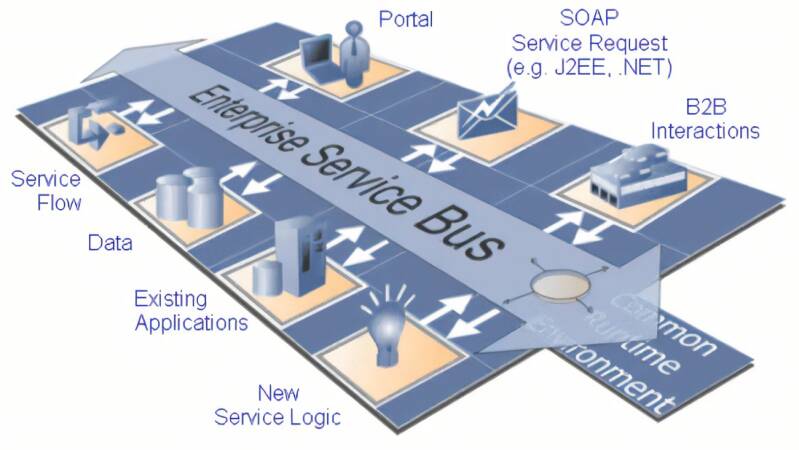

Enterprise Service Bus (ESB)
The Enterprise Service Bus (ESB) is the tool providing message-based abstraction for modularizing services between applications. The ESB acts as a central hub where all of these modularized services get shared, routed, and organized to connect apps and data to one another. The EBS creates a better solution to the EAI hub-and-spoke.
Some of the functionality of ESB features include:
- Since ESBs present themselves as a service using open standards, it eliminates the need to write unique interfaces for each application.
- Integration services can be deployed with minimum changes to applications.
- ESBs rely on industry-standard, open protocols and interfaces to ease new deployments.
ESB deployment uses centralized architectures that is found in the hub-and-spoke model. The ESB serves as the one place to host and control all integration services. But the centralized ESB deployments and architectures come with rigid central governance which doesn't help deliver faster and more adaptive solutions which are the foundations for digital transformation initiatives. ESBs become monolithic applications themselves.

Integration
Integration is deployed with centralized controlling monolithic technologies make security and data integrity a priority. Loosely coupled, cloud-native application architectures developed through agile and DevOps methods need agile integration to connecting resources that combines integration technologies, agile delivery techniques, and cloud-native platforms to improve the speed and security of software delivery. agile integration involves deploying integration technologies like APIs into Linux containers and extending integration across functional areas. Agile integration architecture can be broken down into 3 key capabilities: distributed integration, containers, and application programming interfaces.
Distributed integration has a small IT footprint. It is pattern-based, event-oriented and community-sourced which provides for flexibility.
Containers are cloud-native, individually deployable and scalable for highly available. Containers enable scalability.
Application programming interfaces (API) are well-defined, reusable, well-managed endpoints and rely on the ecosystem influence and use. API allow reusability. These interfaces are modular, lightweight, and comprehensive integration solutions. Moreover, they are open source, open standards, and available on-premise or in the cloud. Streamline integration should be deployed with these comprehensive integration and messaging technologies to connect applications and data across hybrid infrastructures.
For example, OpenShift from RedHat can be used to develop, deploy, manage, and scale applications with containers through a container platform. OpenShift can orchestrate all of those applications automatically and work with other products for agile integration in the cloud.
Streamline integration development with a comprehensive set of integration and messaging technologies to connect applications and data across hybrid infrastructures should be agile, distributed, containerized, and use API-centric solutions. Integration is deployed using a data-driven approach and seamless workload functionality to access to data across the IT infra-structure from the core to cloud to edge.

Robot Process Automation (RPA)
Robotic process automation (RPA) is a software technology that makes it easy to build, deploy, and manage software robots that emulate humans actions interacting with digital systems and software. RPA is used to automate various supply chain processes, including data entry, predictive maintenance and after-sales service support. Furthermore, RPA is used across industries to automate high volume, rote tasks. Telecommunications companies use RPA to configure new services and the associated billing systems for new accounts.
A major purpose for using RPA is to save time and reduce operating expenses. For example, RPA is used Finance & Accounting Invoice Processing, Human Resources Hiring, Retail Inventory Management, Payroll and Customer Support.


RPA works by replicating the actions of an actual human interacting with one or more software applications to perform tasks such as data entry, process standard transactions, or respond to simple customer service queries.
With RPA, software users create software robots, or “bots”, that can learn, mimic, and then execute rules-based business processes. RPA automation enables users to create bots by observing human digital actions. Show the bots what to do, then let them do the work. Robotic Process Automation software bots interact with any application or system the same way people do, but RPA bots operate around the clock, nonstop, much faster with 100% reliability and precision.
RPA is able to copy-paste, scrape web data, make calculations, open and move files, parse emails, log into programs, connect to APIs, and extract unstructured data. Because RPA can adapt to any interface or workflow, there’s no need to change business systems, applications, or existing processes in order to automate.
When RPA is used with AI technologies (aka Intelligent Automation), it enables businesses to operate by seamlessly integrating technology, work processes, and people. For example, RPA+AI will enable (1) Automation for any business process from start to finish, (2) Connect front- and back-office processes, (3) Organize and process complex data, (4) Eliminate errors and exceptions, (5) Strengthen operational security, (6) Ensure compliance, (7) Enhance customer experience, and achieve a very high ROI.

RPA is part Intelligent Automation. Connecting artificial intelligence (AI) technologies like machine learning and natural language processing makes it "intelligent". Intelligent Automation works for many complex business processes. However, most information is not in set format (often referred to as “unstructured data”). For example, Intelligent Document Processing (IDP) is able to capture data from any document, extract relevant information, and organize the data. It is necessary to have the right, usable, data to enables RPA tools to work and execute processes.
It accelerates and scales automation across the organization by recording user activities, discovering documenting business processes, helping analyze process variances to identify automation opportunities with the highest business impact, and generating bot blueprints to automate them.

Automatic process discovery know as task mining is used to uncover business processes by recording user interactions with various systems, such as enterprise solutions (ERP, CRM, BPM, ECM, etc.), personal productivity applications (Microsoft Excel, Outlook, etc.), and terminal and virtual environments. Unlike process mining that reconstruct processes using the data from event logs generated by enterprise solutions, process discovery captures user interactions with any application. It records necessary data such as mouse movements and clicks for identifying RPA opportunities and automatic creation of bots.
Robotic Process Automation has a positive snowball effect on business operations and outcomes. RPA delivers measurable business benefits right out of the gate, such as cost reduction, greater accuracy, delivery speed. It continues to add value as it picks up momentum and spreads across the organization. RPA improves business outcomes like customer satisfaction and enables competitive advantages by freeing humans to solving problems, improving processes, conducting analysis. This results in higher employee engagement and new revenue opportunities.
RPA bots create step-change in employee productivity by accelerating workflows and enabling more work to get done by executing processes independently. In document-intensive industries like financial services, insurance and in the public sector, RPA bots can handle form filling and claims processing all hands-free.
Automating with RPA is enabling industries such as finance, healthcare and life sciences to leverage the reliability of bots to achieve strict compliance standards. Robotic Process Automation in accounting is enabling new levels of speed and precision in order-to-cash and procure-to-pay processes.

RPA is application agnostic so there is no need to upgrade or replace existing systems for RPA to work. Bots enable enterprises to live the dream of eliminating technology siloes by seamlessly connecting across all software tools regardless of function and department. , This results in enterprise-wide efficiencies and collaboration that taps into the true value of human capital investment.

RPA bots help agents interact with customers by doing all the system and data entry work. This results in reduced call handling time (AHT) and a 50% improvement in customer experience at the same time. Industries such as telecommunications and life sciences deploy bots to streamline customer inquiry handling and smoothly respond to spikes in call volumes.
Artificial intelligence (AI) is combined with RPA to create Intelligent Automation. The automation extends by an order of magnitude and is able to draw on the 80% of enterprise data that’s unstructured. For example, in procure-to-pay, it provides for automate invoice processing of non-standard vendor invoices. In insurance, automate extracting claims data and detecting potential fraud. In HR, automate request intake by understanding the employee’s intent.

RPA enables high-volume business processes to be more elastic and able to adapt in uncertain times and changing environments. Any planned or unplanned workflow can be automated by expanding the Digital Workforce when needed.

Big Data
It is estimated that the amount of date collected in 2020 was over 44 zetabytes. The amount of data is expected to increase exponentially each year. Data science is to extract and clean data to get intelligence from raw data for the formulation of actionable insights.
Systematic exploitation of big data, coupled with AI-ML and analytics, reveals opportunities for better business decision making and is being used to solve complex business issues. Big data describes large, hard-to-manage volumes of data – both structured and unstructured – that inundate businesses on a day-to-day basis. But it’s not just the type or amount of data that’s important, it’s what organizations do with the data that matters. Big data can be analyzed for insights that improve and give confidence for making strategic business decisions.
Big Data
Big Data contains greater variety of data, arriving in increasing volumes and with more velocity. Big data is larger, more complex data sets, especially from new data sources. These data sets are so voluminous that traditional data processing software just can't manage them. Big data is classified as Structured Data, Unstructured Data and Semi-Structured Data. There are also four dimensions of Big Data that include volume, variety, velocity and veracity. Big data i describes large, hard-to-manage volumes of data. This includes both structured and unstructured data. The amount of data accumulated continues to increase at an exponential rate. It’s not just the type or amount of data that’s important factor. What organizations do with the data that matters even more.. Big data is analyzed for insights that improve decisions and give confidence for strategic business planning.


The primary characteristics of big data have been described as
Volume. Organizations collect data from a variety of sources, including transactions, smart (IoT) devices, industrial equipment, videos, images, audio, social media and more. In the past, storing all that data would have been too costly – but cheaper storage using data lakes, Hadoop and the cloud have eased the burden.
Velocity. With the growth in the Internet of Things, data streams into businesses at an unprecedented speed and must be handled in a timely manner. Radio Frequency Identification (RFID) tags, sensors and smart meters are driving the need to deal with these torrents of data in near-real time.
Variety. Data comes in all types of formats – from structured, numeric data in traditional databases to unstructured text documents, emails, videos, audios, stock ticker data and financial transactions.
Variability. In addition to the increasing velocities and varieties of data, data flows are unpredictable – changing often and varying greatly. It’s challenging, but businesses need to know when something is trending in social media, and how to manage daily, seasonal and event-triggered peak data loads.
Veracity. Veracity refers to the quality of data. Because data comes from so many different sources, it’s difficult to link, match, cleanse and transform data across systems. Businesses need to connect and correlate relationships, hierarchies and multiple data linkages. Otherwise, their data can quickly spiral out of control.
Big data doesn’t simply revolve around how much data you have. The value lies in how you use it. By taking data from any source and analyzing it, you can find answers that 1) streamline resource management, 2) improve operational efficiencies, 3) optimize product development, 4) drive new revenue and growth opportunities and 5) enable smart decision making. When you combine big data with high-performance analytics, you can accomplish business-related tasks such as:
- Determining root causes of failures, issues and defects in near-real time.
- Spotting anomalies faster and more accurately than the human eye.
- Improving patient outcomes by rapidly converting medical image data into insights.
- Recalculating entire risk portfolios in minutes.
- Sharpening deep learning model to accurately classify and react to changing variables.
- Detecting fraudulent behavior before it affects your organization.
Data scientists analyzes and looks for insights in data. Data engineers build pipelines focused on DataOps. Data officers ensure data is reliable and managed responsibly. Synergy among roles drives analytics success.
Big data projects demand intense resources for data processing and storage. Working together, big data technologies and cloud computing provide a cost-effective way to handle all types of data. This leads to a winning combination of agility and elasticity.

Big data is a big deal for industries. The onslaught of IoT and other connected devices has created a massive uptick in the amount of information organizations collect, manage and analyze. Big data comes the potential to unlock big insights. Today’s exabytes of big data open countless opportunities to capture insights that drive innovation. Big Data is often used for more accurate forecasting to increased operational efficiency and better customer experiences.

Big Data can be distinguished from structured data which is found in a data warehouse. A data warehouse is specially designed for data analytics, which involves reading large amounts of data to understand relationships and trends across the data. A database is used to capture and store data, such as recording details of a transaction. Data warehouse uses extract, transform and load (ETL) processes. The data warehouses store vast amounts of structured data in highly regimented ways. They require that a rigid, predefined schema exists before loading the data. This normally uses a star or snowflake schema. The schema in a data warehouse is defined “on write.” ETL processes kick out error reports, generate logs, and send errant records to exception files and tables to be addressed later.
Because of this rigidity and the ways in which they work, data warehouses support partial or incremental ETL. Depending on the severity of the issue, it often involves reloading portions of its data warehouse when something goes wrong. Data Warehouses are populated periodically by data refreshes via regular cycles. Data stored in traditional data warehouses remains valuable today.

Data Lakes
Data Lakes were developed to supplement data warehouses and provide a more flexible platform for any type of data. Data lakes work with other technologies to provide fast insights that lead to better decisions. The data lake provide a resting place for raw data in its native format until it’s needed.” Data lies dormant until it is needed. When accessing data lakes, users determine:
- The specific data types and sources they need.
- How much they need.
- When they need it.
- The types of analytics that they need to derive.
This would not be possible in a data warehouse. One particular schema almost certainly will not fit every business need. The data may ultimately arrive in a way that renders it virtually useless for evolving purposes. The data lake schema is defined “on read. The data lake still requires a schema, but that schema is not predefined. It’s ad hoc. Data is applied to a plan or schema as users pull it out of a stored location – not as it goes in. Data lakes keep data in its unaltered state; it doesn’t define requirements until users query the data.
The data lake offers the ability to query smaller, more relevant and more flexible data sets. As a result, query times can drop to a fraction of what they would have been in a data mart, data warehouse or relational database.
The data lake emphasizes the flexibility and availability of data. It can provide users and downstream applications with schema-free data. Data resembles its “natural” or raw format regardless of origin. Data lake applications do not support partial or incremental loading. This is the primary basic way the data lake differs from the data warehouse. Data cannot loaded or portions reloaded into a data lake.


The data lake doesn’t hold only one type of data. Data lakes can house all types of data. This can be structured, semi-structured and unstructured. Data warehouses were not built to handle vast streams of unstructured data. The difference between “on write” and “on read” lends itself to vastly faster response times and, by extension, analytics.
When conceptualizing the need for data lakes, perhaps it’s best to think of Hadoop – the open-source, distributed file system that many organizations adopted over the years. Hadoop grew for many reasons, not the least of which is that it fulfilled a genuine need that relational database management systems (RDBMSs) could not address. To be fair, its open-source nature, fault tolerance and parallel processing place high on the list as well.
RDBMSs weren’t designed to handle gigabytes or petabytes of unstructured data. Hadoop was developed as an open source, fault tolerant, parallel processing distributed file system for large amounts of data. Data lakes rely upon ontologies and metadata to make sense out of data loaded into them. Each data element in a lake inherits a unique identifier assigned with extensive metadata tags.
Business Intelligence
Business intelligence (BI) is a technology-driven process for analyzing data and delivering actionable information that helps executives, managers and workers make informed business decisions. Business intelligence, or BI, is a type of software that can harness the power of data within an organization. These insights can help companies make strategic business decisions that increase productivity, improve revenues, and enhance growth.

Business intelligence has five stages that include Data sourcing, Data analysis, Situation awareness, Risk assessment and Decision support. Business intelligence (BI) combines business analytics, data mining, data visualization, data tools and infrastructure to make more data-driven decisions. Data to drive change, eliminate inefficiencies, and quickly adapt to market or supply changes. Modern BI solutions prioritize flexible self-service analysis, governed data on trusted platforms, empowered business users, and speed to insight.
Business intelligence covers the processes and methods of collecting, storing, and analyzing data from business operations or activities to optimize performance. All of these things come together to create a comprehensive view of a business to help make better, actionable decisions. Today business intelligence has evolved to include more processes and activities to help improve performance.
- Data mining: Using databases, statistics and machine learning to uncover trends in large datasets.
- Reporting: Sharing data analysis to stakeholders so they can draw conclusions and make decisions.
- Performance metrics and benchmarking: Comparing current performance data to historical data to track performance against goals, typically using customized dashboards.
- Descriptive analytics: Using preliminary data analysis to find out what happened.
- Querying: Asking the data specific questions, BI pulling the answers from the datasets.
- Statistical analysis: Taking the results from descriptive analytics and further exploring the data using statistics such as how this trend happened and why.
- Data visualization: Turning data analysis into visual representations such as charts, graphs, and histograms to more easily consume data.
- Visual analysis: Exploring data through visual storytelling to communicate insights on the fly and stay in the flow of analysis.
- Data preparation: Compiling multiple data sources, identifying the dimensions and measurements, preparing it for data analysis.

Taking care of business

Business intelligence can help companies make better decisions by showing present and historical data within their business context. Analysts can leverage BI to provide performance and competitor benchmarks to make the organization run smoother and more efficiently. Analysts can also more easily spot market trends to increase sales or revenue. A few ways that business intelligence can help companies make smarter, data-driven decisions:
- Identify ways to increase profit
- Analyze customer behavior
- Compare data with competitors
- Track performance
- Optimize operations
- Predict success
- Spot market trends
- Discover issues or problems
Business intelligence (BI) is an umbrella term for the technology that enables data preparation, data mining, data management, and data visualization. Business intelligence tools and processes allow end users to identify actionable information from raw data, facilitating data-driven decision-making within organizations across various industries.
There are a number of BI tools in the marketplace, which aid business users in analyzing performance metrics and extracting insights in real time. These tools focus on self-service capabilities and enabling decision-makers to recognize performance gaps, market trends, or new revenue opportunities more quickly. BI applications are commonly used to make informed business decisions. As businesses migrate workloads to the cloud, adoption of BI software continues to increase. Business intelligence focuses narrowly on what is happening in the business. While business analytics more broadly includes solutions that help you leverage that insight to plan for the future. Business intelligence uses descriptive analytics to formulate conclusions about historical and current performance, providing context around changes in key performance indicators (KPIs).


Business analytics and business intelligence are inclusive of prescriptive and predictive analytics practices, which help advise decision-makers on potential future outcomes. Both BI and business analytics solutions enable stakeholders to make better decisions, and these should be viewed as complementary to one another. Business analytics and data analytics tend to be used interchangeably. But business analytics is a merely a subset of data analytics, as the scope of data analytics can refer to any analysis of data. Business analytics focuses on discovering information which can improve business decision-making.
BI platforms are have dash-boarding, ad hoc reporting and data visualization capabilities At the core, BI rely on data warehouses, ETL, and OLAP. After data is pre-processed and aggregated, it is fed into one central repository, such as a data warehouse or data mart, which supports business analytics and reporting tools. For larger data sets, businesses typically use an open source data storage framework known as Apache Hadoop. BI solutions rely on a data integration process that combines data from multiple data sources into a single, consistent data store that is loaded into a data warehouse or other target system. ETL is the three steps in this process, which are extract, transform and load.
OLAP is an acronym which stands for online analytical processing. This technology extracts big data from relational tables and reorganizes it into a multidimensional format, enabling fast processing and insightful data analysis.

Natural language processing (NLP) refers to the branch of artificial intelligence that enables computers to understand text and spoken words in a similar way to human beings. BI has started to incorporate this technology to access business information in new ways.
It is highly valuable for BI solutions to provide a one-stop-shop across the entire analytics journey. This starts with data. Automatically identifying any problems in the data and suggesting ways to combine different data sources allows users to adapt and customize datasets and dashboards as needed. The process makes it faster and easier for a business user to cleanse, refine and combine data modules so that they end up with exactly the data they need to drive powerful visualizations and uncover new insights.

Reporting and dash-boarding are at the heart of a modern approach to analytics. Businesses rely on regular, structured reporting to run their business. These formal reports collect and disseminate the crucial details that support good decision-making, and they provide jumping-off points for further exploration of trends, threats and opportunities. AI features embedded in modern BI solutions learn from users to make it easier to identify visualizations that have the highest impact for discovering and communicating insights.
Avant-Grade-Technologies used all of these technologies in DevOps and with BigData . The objective is to use BigData to and Structured Data for decision making. All of these systems are automated and integrated in other business systems, such as marketing, finance, engineering and human resources. All of these methods are used together to provide a holistic solution and improve decision making.